
Pythonの『Selenium』というサードパーティ製のモジュールを用いれば、Google ChromeやFirefoxなどのブラウザで行っている操作を自動化することができます。
ある特定のWebページからデータを収集したりやファイルをダウンロードしたり…。
下のGIF画像は、GoogleにアクセスしてSeleniumと検索して、検索1位の記事のタイトルと飛び先のURLを取得するサンプルプログラムです。
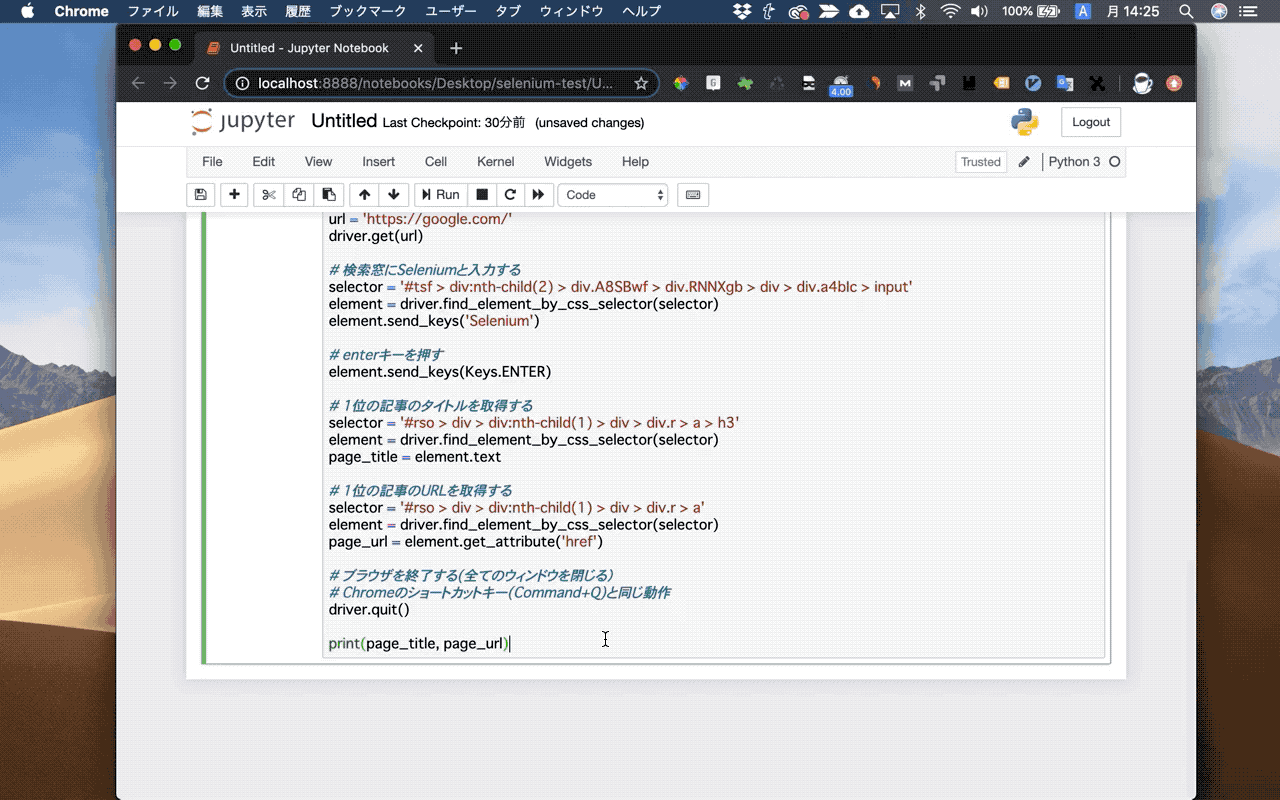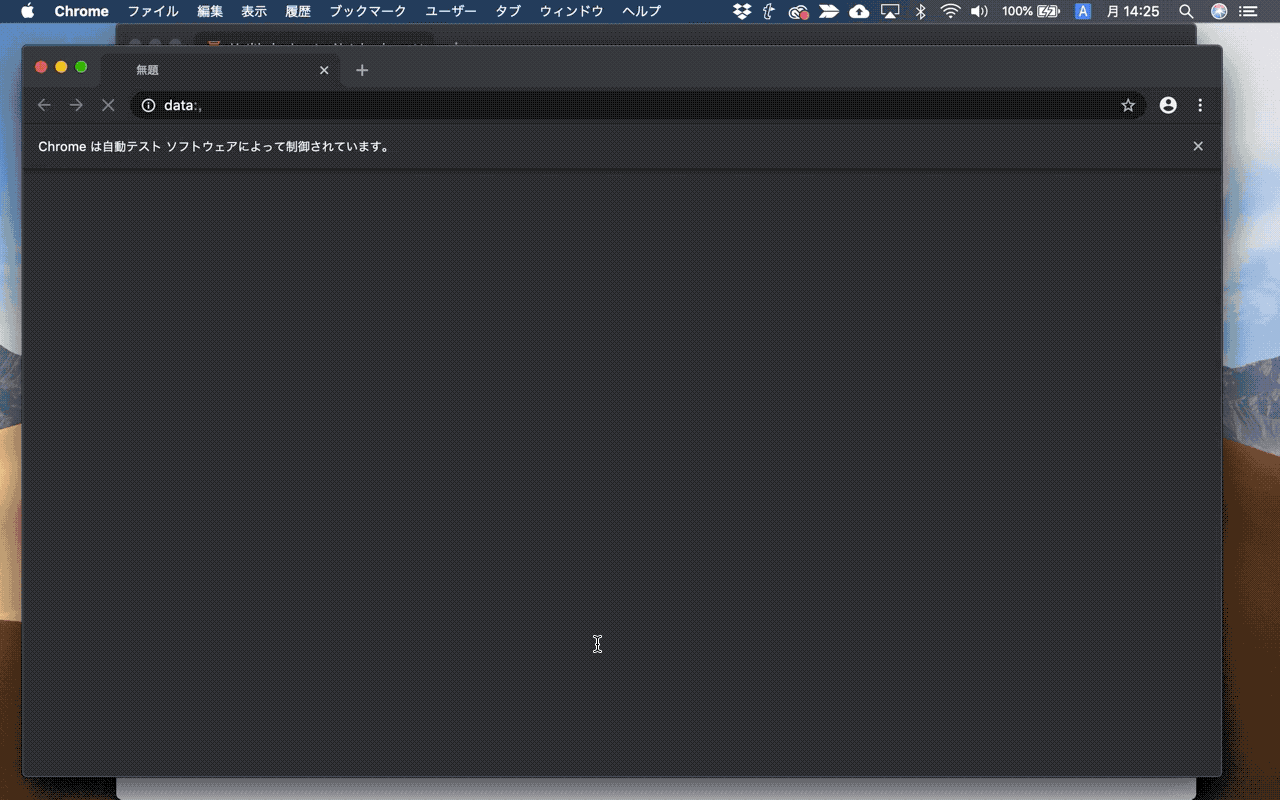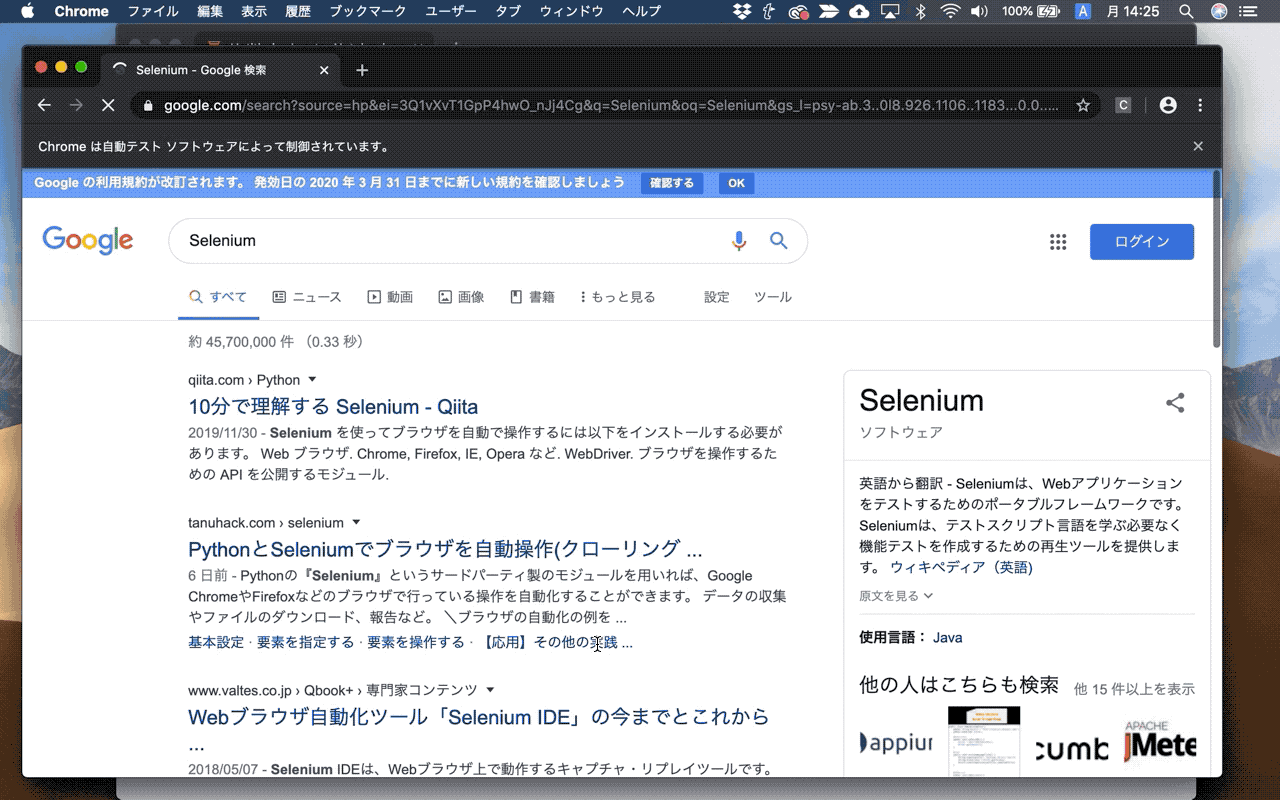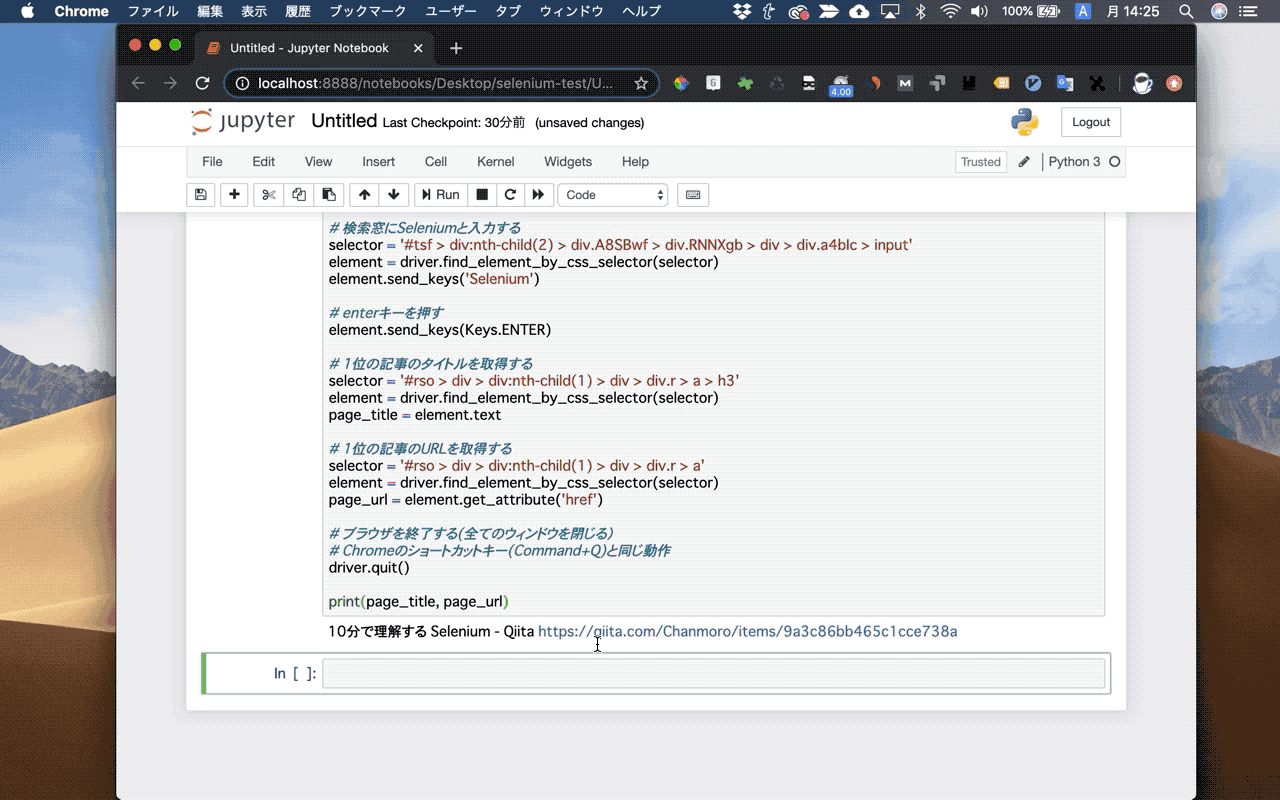
Seleniumで出来ることを専門用語を使って説明すると、『ブラウザのクローリングとスクレイピングが簡単にできるようになる』ということです。
 たぬ
たぬ
ということで今回の記事は、Seleniumの導入から私自身がよく使うSeleniumのベストプラクティスまでの総集編です。自分への備忘録も含め、Python初学者の参考になれば嬉しいなと切に願ってます。
| OS | MacOS Mojave 10.14.5 |
| Google Chrome | 80.0.3987.122 |
| ChromeDriver | 80.0.3987.106 |
| Python | 3.7.1 |
| Selenium | 3.13.0 |

データサイエンティスト / ブロガー
たぬ
tanu
福岡在住のデータサイエンティスト。Pythonでルーチンワークを瞬殺する仕組みを作ることやデータを視覚化することが得意です。
初期設定
PythonでSeleniumを使うためには、これから紹介する2つの設定を行う必要があります。
- Seleniumをインストールする
- WebDriverを任意の階層にダウンロードする
Seleniumをインストールする
ターミナルでpipコマンド等を使って、本番環境もしくは仮想環境(venv、pyenvなど)にSeleniumをインストールします。
pip install seleniumWebDriverをダウンロードする
Seleniumを使うには、操作するブラウザに対応したWebDriverのダウンロードが必要不可欠です。
WebブラウザはChrome、Safari、Firefox、Edge、Operaといろいろありますが、今回はGoogle Chrome版のWebDriverをダウンロードします。
公式サイトからChromeのWebDriverの最新版をダウンロードします。
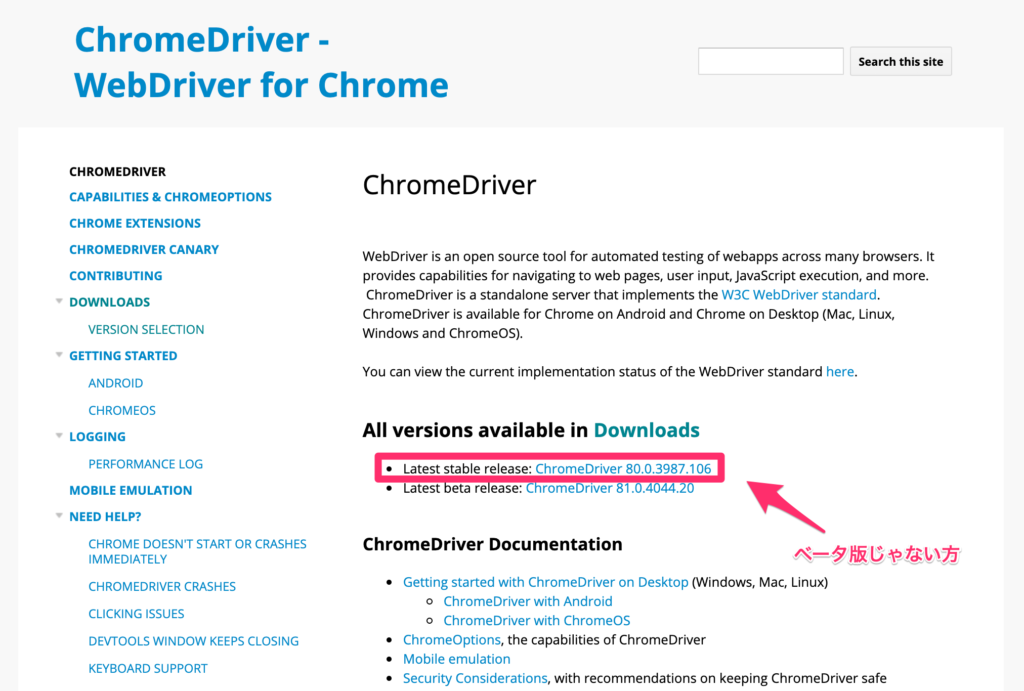
今回はMacで実行するので、Mac用のドライブをダウンロードします。
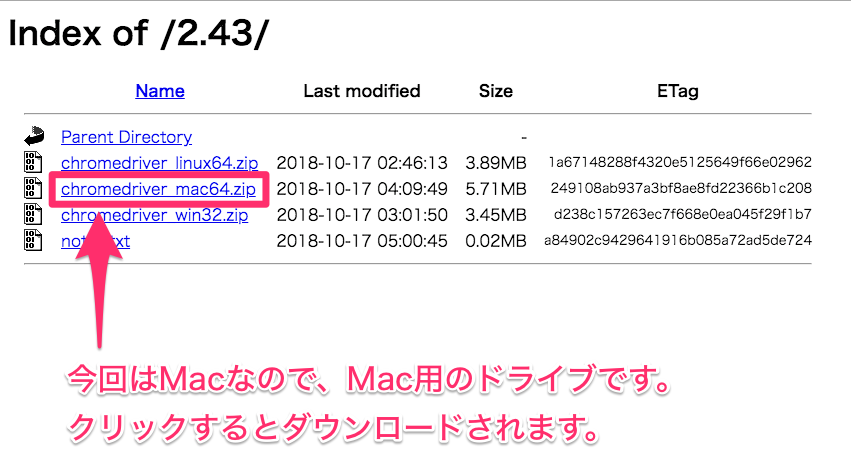
WebDriverの保存場所はどこでも良いので、自分が分かりやすい場所にしましょう。
今回は例としてデスクトップに『Selenium』というフォルダを新規作成して、その中にWebDriverを格納します。
基本設定
モジュールのインポート
まず、PythonでSeleniumを使うために必要なモジュールをインポートします。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.alert import Alert
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutExceptionWebDriverのオプション設定
次に、あらゆる環境(ローカル、サーバー上)でSeleniumが動作するようにChromeOptionsを設定します。
# Seleniumをあらゆる環境で起動させるChromeオプション
options = Options()
options.add_argument('--disable-gpu');
options.add_argument('--disable-extensions');
options.add_argument('--proxy-server="direct://"');
options.add_argument('--proxy-bypass-list=*');
options.add_argument('--start-maximized');
# options.add_argument('--headless'); # ※ヘッドレスモードを使用する場合、コメントアウトを外すヘッドレスモードとは、画面やページ遷移を表示せずに動作するモードです。Herokuなどのサーバー上でSeleniumを動かす場合は必須になります。
WebDriver(ブラウザ)の起動
DRIVER_PATH = '{{ WebDriverのパスを指定(絶対でも相対パスでも可) }}'
# DRIVER_PATH = '/Users/Kenta/Desktop/Selenium/chromedriver' # ローカル
# DRIVER_PATH = '/app/.chromedriver/bin/chromedriver' # heroku
# ブラウザの起動
driver = webdriver.Chrome(executable_path=DRIVER_PATH, chrome_options=options)Webページにアクセス
# Webページにアクセスする
url = '{{ クローリング/スクレイピングするURL }}'
driver.get(url)サンプルプログラム
ここでは章のまとめとして、GoogleにアクセスしてSeleniumと検索して、検索1位の記事のタイトルと飛び先のURLを取得するサンプルプログラムを紹介します。
Seleniumのプログラムの全容がつかめると思うので、ぜひトライしてみて下さいね。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.alert import Alert
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
#
# Seleniumをあらゆる環境で起動させるオプション
#
options = Options()
options.add_argument('--disable-gpu');
options.add_argument('--disable-extensions');
options.add_argument('--proxy-server="direct://"');
options.add_argument('--proxy-bypass-list=*');
options.add_argument('--start-maximized');
# options.add_argument('--headless'); # ※ヘッドレスモードを使用する場合、コメントアウトを外す
#
# Chromeドライバーの起動
#
DRIVER_PATH = '{{ ChromeDriverのPath }}'
driver = webdriver.Chrome(executable_path=DRIVER_PATH, chrome_options=options)
#
#
# クローリング/スクレイピング
#
#
# Googleにアクセスする
url = 'https://google.com/'
driver.get(url)
# 検索窓にSeleniumと入力する
selector = '#tsf > div:nth-child(2) > div.A8SBwf > div.RNNXgb > div > div.a4bIc > input'
element = driver.find_element_by_css_selector(selector)
element.send_keys('Selenium')
# enterキーを押す
element.send_keys(Keys.ENTER)
# 1位の記事のタイトルを取得する
selector = '#rso > div > div:nth-child(1) > div > div.r > a > h3'
element = driver.find_element_by_css_selector(selector)
page_title = element.text
# 1位の記事のURLを取得する
selector = '#rso > div > div:nth-child(1) > div > div.r > a'
element = driver.find_element_by_css_selector(selector)
page_url = element.get_attribute('href')
# ブラウザを終了する(全てのウィンドウを閉じる)
# Chromeのショートカットキー(Command+Q)と同じ動作
driver.quit()
print(page_title, page_url)
# 10分で理解する Selenium - Qiita https://qiita.com/Chanmoro/items/9a3c86bb465c1cce738aページ全体の操作
タイトル/URLを取得する
# タイトルを取得する
title = driver.title
# URLを取得する
url = driver.current_url戻る/進む/更新する
# ブラウザバック(戻る)
driver.back()
# ブラウザバックの取り消し(進む)
driver.forward()
# ページを更新(リロード)する
driver.refresh()閉じる/終了する
# ページを閉じる(Command + W と同じ)
driver.close()
# ブラウザを終了する(Command + Q と同じ)
driver.quit()ウィンドウを最大化する
driver.maximize_window()でもウィンドウを最大化できるみたいですが、出来ないといった声が多かったので別の方法を紹介します。
ChromeOptionsにoptions.add_argument('--kiosk')を追加することで画面が最大化されます。
# Seleniumをあらゆる環境で起動させるChromeオプション
options = Options()
options.add_argument('--disable-gpu');
options.add_argument('--disable-extensions');
options.add_argument('--proxy-server="direct://"');
options.add_argument('--proxy-bypass-list=*');
options.add_argument('--start-maximized');
# options.add_argument('--headless');
options.add_argument('--kiosk') # <= 追加するスクリーンショットを取る
screenshot_path = '{{ 保存先のパス(絶対パスまたは相対パス) }}'
driver.save_screenshot(screenshot_path)アラートダイアログの操作
# YESかNOかのダイアログアラートが出現したとき
Alert(driver).accept() # YESを押す
Alert(driver).dismiss() # NOを押す操作するウィンドウを切り替える
リンクテキストのtarget="_blank"で別ウィンドウに飛ばされたときに使います。
# ウィンドウハンドルを取得する(list)
handle_array = driver.window_handles
# 一番最後に表示されたブラウザにドライバーを切り替える
driver.switch_to.window(handle_array[-1])
 [Python]Seleniumで操作するウィンドウを切り替える2つの方法を紹介
[Python]Seleniumで操作するウィンドウを切り替える2つの方法を紹介
要素の指定
Webページの要素(element)は、id属性、class属性、name属性、CSSセレクタ、XPath等で指定することが出来ます。
| 指定先 | メソッド |
|---|---|
id属性 |
driver.find_element_by_id('{{ ID }}') |
class属性 |
driver.find_element_by_class_name('{{ CLASS }}') |
name属性 |
driver.find_element_by_name('{{ NAME }}') |
| CSSセレクタ | driver.find_element_css_selector('{{ CSSセレクタ }}') |
| XPath | driver.find_element_by_xpath('{{ XPath }}') |
個人的にオススメなのは、CSSセレクタを使用して要素を指定するやり方です。
# 要素を指定する
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)なぜかと言うと、ID属性やclass属性はCSSセレクタで指定出来る上に、後述するBeautiful Soupモジュールを使ったスクレイピングのやり方と親和性が高いからです。
6.実践テクニック集 > 6-3.BeautifulSoupと組み合わせる
よく使うCSSセレクタまとめ
- タグ
- ID
- class
タグ
タグ名h2
------------
<div>
<h2>基本のセレクタ</h2> # Here!
<p>文章1</p>
<p>文章2</p>
<p>文章3</p>
</div>ID名
#ID名#title
------------
<div>
<h2 id="title">基本のセレクタ</h2> # Here!
<p>文章1</p>
<p>文章2</p>
<p>文章3</p>
</div>class名
.class名.red
------------
<div>
<h2>基本のセレクタ</h2>
<p class="red">文章1</p> # Here!
<p class="red">文章2</p> # Here!
<p>文章3</p>
</div>- ある属性名を含む要素だけ
- 【完全一致】ある属性名で指定した値と一致した要素だけ
- 【前方一致】ある属性名の値が指定した値で始まる要素だけ
- 【後方一致】ある属性名の値が指定した値で終わる要素だけ
- 【部分一致】ある属性名の値が指定した値を含む要素だけ
ある属性名を含む要素だけ
タグ名[属性名]a[target]
------------
<p><a href="#">内部リンク</a></p>
<p><a href="xxx" target="_blank">外部リンク</a></p> # Here!【完全一致】ある属性名で指定した値と一致した要素だけ
タグ名[属性名="値"]input[type="text"]
------------
<input type="text"> # Here!
<input type="password">
<input type="radio">【前方一致】ある属性名の値が指定した値で始まる要素だけ
タグ名[属性名^="値"]p[class^="en"]
------------
<p class="english">文章1</p> # Here!
<p class="enable">文章2</p> # Here!
<p class="japan">文章3</p>
<p class="coen">文章4</p>【後方一致】ある属性名の値が指定した値で終わる要素だけ
タグ名[属性名$="値"]p[class$="n"]
------------
<p class="english">文章1</p>
<p class="enable">文章2</p>
<p class="japan">文章3</p> # Here!
<p class="coen">文章4</p> # Here!【部分一致】ある属性名の値が指定した値を含む要素だけ
タグ名[属性名*="値"]p[class*="en"]
------------
<p class="english">文章1</p> # Here!
<p class="enable">文章2</p> # Here!
<p class="japan">文章3</p>
<p class="coen">文章4</p> # Here!- 複数のセレクタを同時にみたす要素を指定
- カンマ区切りで複数のセレクタを指定
- 絞り込み指定(半角スペース区切り)
- 『>』で子要素にのみ指定
- 『+』で同じ階層の直後の要素にのみ指定
- 『~』で同じ階層の後ろに並ぶ要素に指定
複数のセレクタを同時にみたす要素を指定
selector1selector2.color.blue
------------
<ul>
<li>1つ目のliタグ</li>
<li class="color">2つ目のliタグ</li>
<li class="blue">3つ目のliタグ</li>
<li class="color blue">4つ目のliタグ</li> # Here!
</ul>カンマ区切りで複数のセレクタを指定
selector1, selector2.red, .blue
------------
<ul>
<li>1つ目のliタグ</li>
<li class="red">2つ目のliタグ</li> # Here!
<li class="green">3つ目のliタグ</li>
<li class="blue">4つ目のliタグ</li> # Here!
</ul>絞り込み指定(半角スペース区切り)
selector1 selector2nav ul .example
------------
<nav>
<li class="example">1つ目のliタグ</li>
<ul>
<li class="example">2つ目のliタグ</li> # Here!
<li>3つ目のliタグ</li>
<li>4つ目のliタグ</li>
</ul>
</nav>『>』で子要素にのみ指定
selector1 > selector2.example > p
------------
<div class="example">
<p>文章1</p> # Here!
<div>
<p>文章2</p>
</div>
</div>『+』で同じ階層の直後の要素にのみ指定
selector1 + selector2.example + li
------------
<ul>
<li>1つ目のliタグ</li> # Here!
<li class="example">2つ目のliタグ</li>
<li>3つ目のliタグ</li> # Here!
<li>4つ目のliタグ</li>
</ul>『~』で同じ階層の後ろに並ぶ要素に指定
selector1 ~ selector2.example ~ li
------------
<ul>
<li>1つ目のliタグ</li> # Here!
<li class="example">2つ目のliタグ</li>
<li>3つ目のliタグ</li> # Here!
<li>4つ目のliタグ</li> # Here!
</ul>- 最初の要素のみ
- 最後の要素のみ
- n番目の要素のみ
- nの倍数番目の要素のみ
最初の要素のみ
selector:first-childul li:first-child
------------
<ul>
<li>1つ目のliタグ</li> # Here!
<li>2つ目のliタグ</li>
<li>3つ目のliタグ</li>
<li>4つ目のliタグ</li>
</ul>最後の要素のみ
selector:last-childul li:last-child
------------
<ul>
<li>1つ目のliタグ</li>
<li>2つ目のliタグ</li>
<li>3つ目のliタグ</li>
<li>4つ目のliタグ</li> # Here!
</ul>n番目の要素のみ
selector:nth-child(n)ul li:nth-child(3)
------------
<ul>
<li>1つ目のliタグ</li>
<li>2つ目のliタグ</li>
<li>3つ目のliタグ</li> # Here!
<li>4つ目のliタグ</li>
</ul>nの倍数番目の要素のみ
selector:nth-child(n)ul li:nth-child(2n-1)
------------
<ul>
<li>1つ目のliタグ</li> # Here!
<li>2つ目のliタグ</li>
<li>3つ目のliタグ</li> # Here!
<li>4つ目のliタグ</li>
</ul>- あるセレクタを含まない要素を指定
- あるセレクタとあるセレクタを含まない要素を指定
あるセレクタを含まない要素を指定
selector1:not(selector2)ul > li:not(.blue)
------------
<ul>
<li>1つ目のliタグ</li> # Here!
<li class="red">2つ目のliタグ</li> # Here!
<li class="green">3つ目のliタグ</li> # Here!
<li class="blue">4つ目のliタグ</li>
</ul>ul > li:not(:first-child)
------------
<ul>
<li>1つ目のliタグ</li>
<li>2つ目のliタグ</li> # Here!
<li>3つ目のliタグ</li> # Here!
<li>4つ目のliタグ</li> # Here!
</ul>あるセレクタとあるセレクタを含まない要素を指定
selector1:not(selector2):not(selector3)ul > li:not(.blue):not(.red)
------------
<ul>
<li>1つ目のliタグ</li> # Here!
<li class="red">2つ目のliタグ</li>
<li class="green">3つ目のliタグ</li> # Here!
<li class="blue">4つ目のliタグ</li>
</ul>ul > li:not(:first-child):not(:last-child)
------------
<ul>
<li>1つ目のliタグ</li>
<li>2つ目のliタグ</li> # Here!
<li>3つ目のliタグ</li> # Here!
<li>4つ目のliタグ</li>
</ul>開発ツールでCSSセレクタを取得する
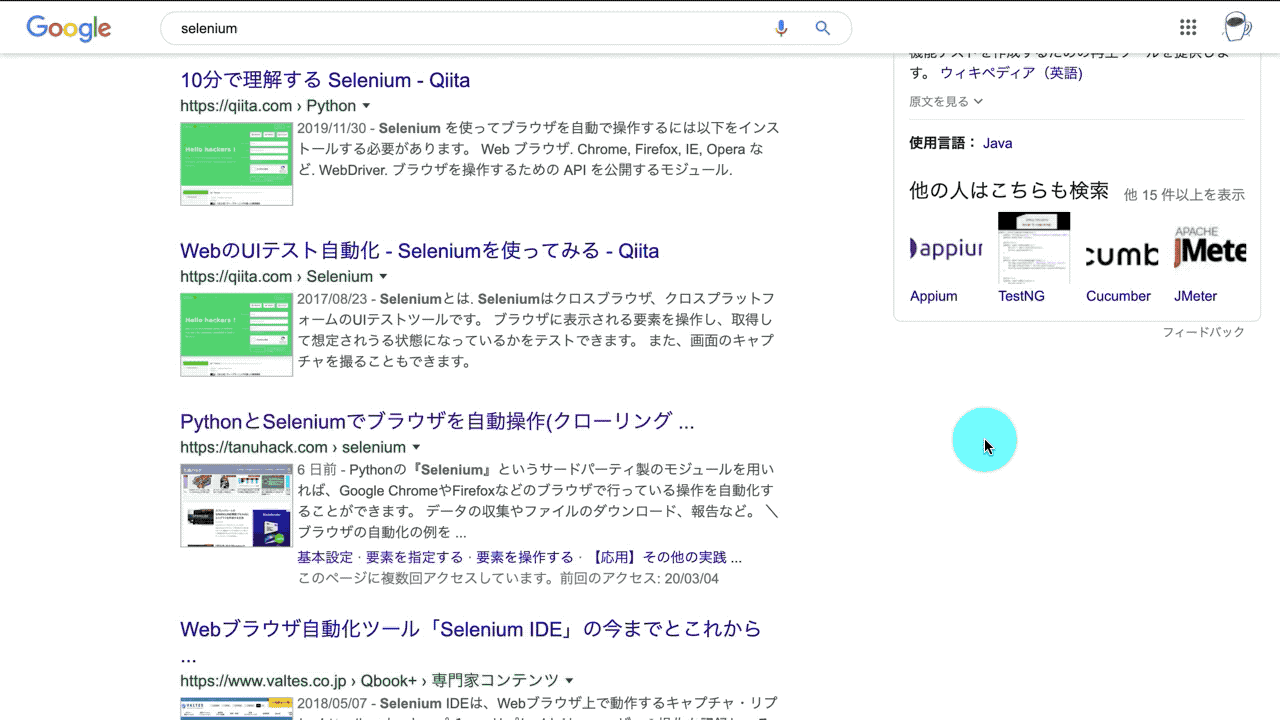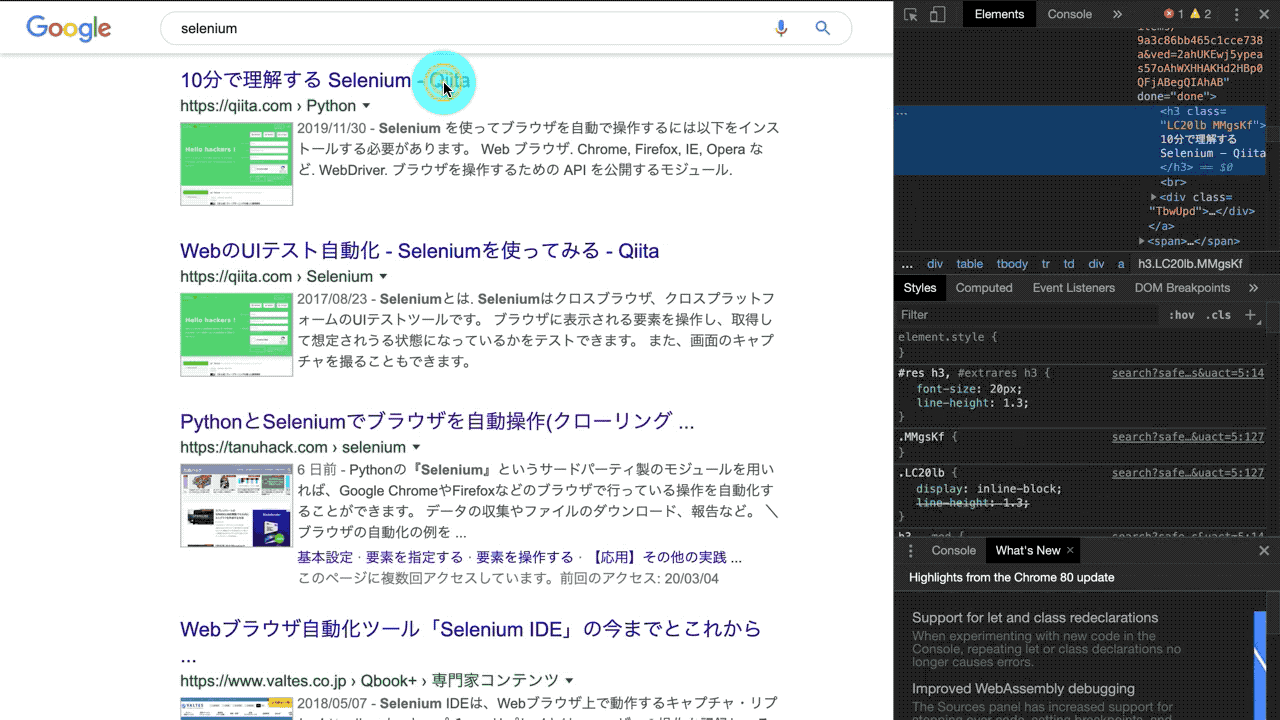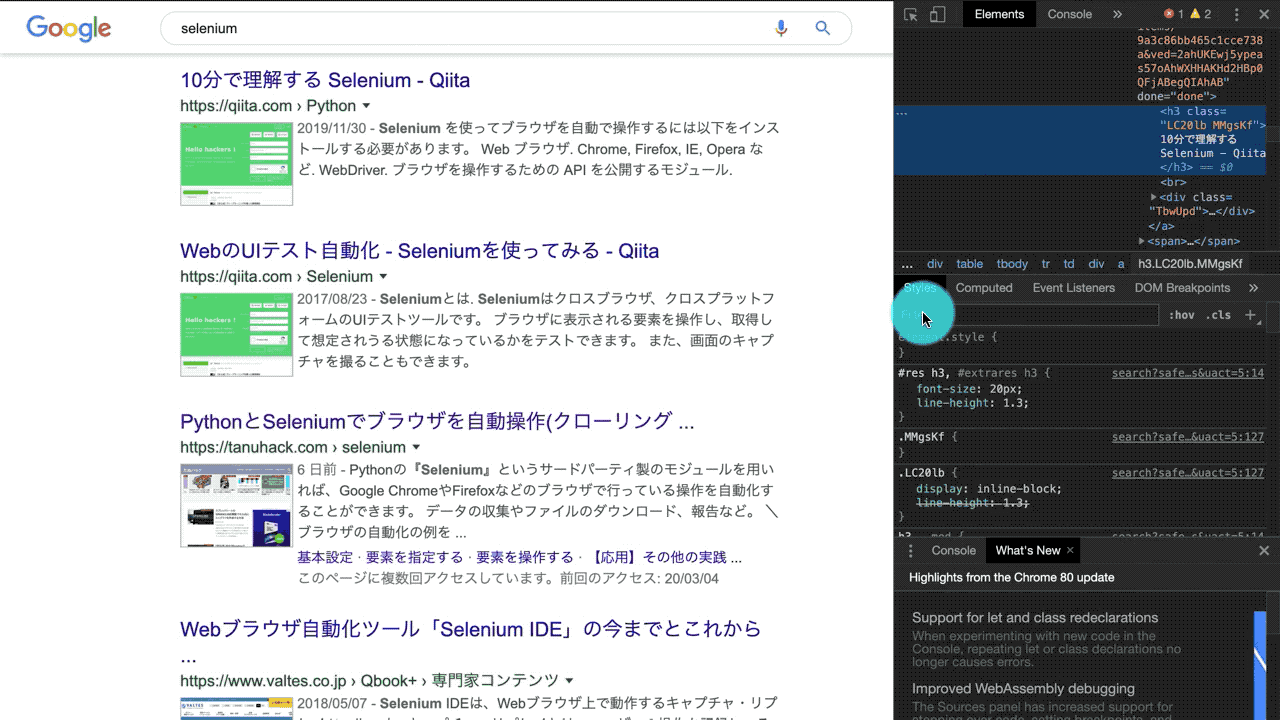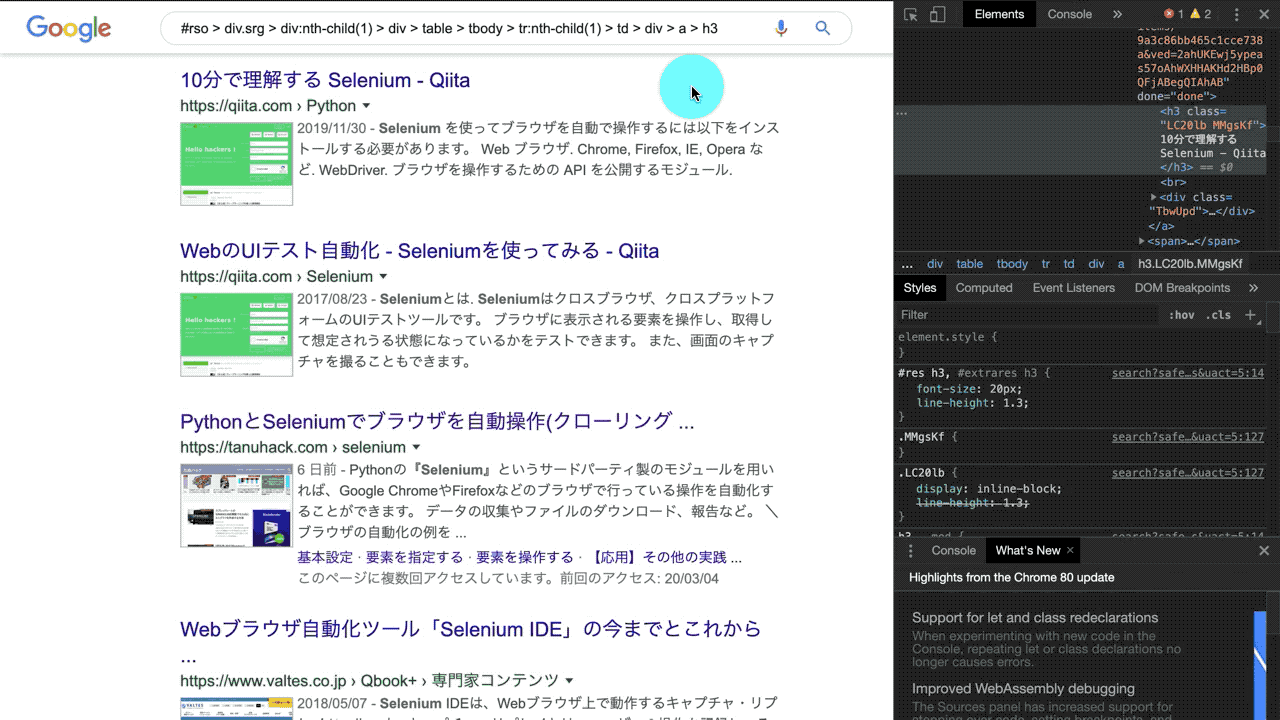
Chromeの開発ツール(ディベロッパーツール)を使うと、操作する要素のCSSセレクタを一発で取得することができます。
『要素をダイレクトで指定』→『右クリック』→『Copy selector』で簡単にCSSセレクタを取得することができます。
要素の操作
前章で要素を指定できたら、今度は指定した要素に実行したい処理を設定します。
# 要素を指定する
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)
# 要素を操作する
element.xxxテキスト/属性値を取得する
# 要素を指定する
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)
# テキストを取得する
element.text
# 属性値を取得する
element.get_attribute('属性名')テキストを入力/削除する
# 要素を指定する
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)
# テキストを入力する
element.send_keys('{{ inputやtextareaに入力する文字列 }}')
# テキストを削除する
element.clear()まれにWebページによって、element.clear()で文字列を削除できない場合があります。
そういうときは、消したい文字数分だけバックスペースキーを押して、無理やり削除します。
# 要素を指定する
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)
# 文字数分バックスペースキーを押す
for _ in range(len(element.text)):
element.send_keys(Keys.BACK_SPACE)クリックする
# 要素をクリックする
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)
element.click()まれにWebページによって、element.click()でクリック出来ないことがあります。
そういうときは、driver.execute_scriptメソッドを使用して、JavaScriptを呼び出し、無理やりクリックさせます。
# 要素をクリックする(JavaScript)
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)
driver.execute_script('arguments[0].click();', element)また、検索フォームなどでクリックする要素がない場合は、エンターキーを押すことでクリックと同等のアクションを行うこともできます。
# エンターキーを押す
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)
element.send_keys(Keys.ENTER)特殊キーを押す
# 要素を指定する
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)
# エンターキー
element.send_keys(Keys.ENTER)
# バックスペースキー
element.send_keys(Keys.BACK_SPACE)
# エスケープキー
element.send_keys(Keys.ESCAPE)
# タブキー
element.send_keys(Keys.TAB)他の特殊キーを知りたい人は、こちらを参考にして下さい。
select要素を操作する
SELECT要素のOPTIONはelement.click()などでクリックしても反応しません!
選択する
# 要素を指定する(※Selectを指定する)
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)
# 【オススメ】option要素のvalue属性値で選択する
Select(element).select_by_value('{{ value属性値 }}')
# option要素のインデックスで選択する
Select(element).select_by_index('{{ インデックス }}')
# option要素の表示テキストで選択する
Select(element).select_by_visible_text('{{ 文字列 }}')選択解除する
# 要素を指定する(※Selectを指定する)
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)
# 【オススメ】option要素のvalue属性値で選択解除する
Select(element).deselect_by_value('{{ value属性値 }}')
# option要素のインデックスで選択解除する
Select(element).deselect_by_index('{{ インデックス }}')
# option要素の表示テキストで選択解除する
Select(element).deselect_by_visible_text('{{ 文字列 }}')
# すべて選択解除する
Select(element).deselect_all()実践テクニック集
待機処理
Seleniumのエラーの原因の95%以上は、Seleniumの処理が速すぎて、指定した要素が見つからないことだと思います。
通常の人間が行うブラウザ操作であれば、ページの読み込みが完了していないのに、ボタンをクリックしたりテキストを取得したりなんて出来ませんよね。
つまり、Web Driverに正しく『待ち』の時間を設定してあげることでSeleniumのエラーは、大幅に減少します。
暗黙的な待機
implicitly_waitメソッドを使用すると、暗黙的な待機時間を設定することができます。デフォルト:0秒。
driver.implicitly_wait(10) # 秒一度設定すると、全てのfind_element等の処理時に、要素が見つかるまで指定した最大時間待機させるようにすることができます。
明示的な待機
暗黙的な待機(implicitly_wait)で対応しきれなかった処理に対して、WebDriverWait.untilメソッドで、任意のHTMLの要素が特定の状態になるまで待つ明示的な待機時間を設定することができます。
# 指定した要素が表示されるまで、明示的に30秒待機する
selector = '{{ CSSセレクタ }}'
element = WebDriverWait(driver, 30).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, selector))
)先程、WebDriverWait.untilメソッドの説明を、任意のHTMLの要素が『特定の状態になる』と説明をしました。
例では、visibility_of_element_locatedメソッドが、ここで言う『特定の状態になる』部分を指しています。
| メソッド | 説明 |
|---|---|
alert_is_present |
Alertが表示されるまで待機する |
element_to_be_clickable |
要素がクリック出来る状態になるまで待機する |
visibility_of_element_located |
指定した要素が表示されるまで待機する |
invisibility_of_element_located |
指定した要素が非表示になるまで待機する |
text_to_be_present_in_element |
指定したテキストが表示されるまで待機する |
presence_of_element_located |
指定した要素がDOM上に現れるまで待機する |
他にも気になる人はこのページで確認して下さい。
最終手段
暗黙的な待機(implicitly_waitメソッド)と明示的な待機(expected_conditionsクラス)でも、うまくいかなかった場合の最終手段を紹介します。
それは、Pythonの標準ライブラリのtimeクラスのsleepメソッドを使用して、要素が表示されていようがいまいが強制的に指定した時間だけプログラムをスリープさせる方法です。
import time
time.sleep(30) # 秒人間っぽく待機する
NumPyのrandomクラスを用いて、待機時間に幅をもたせます。
import numpy as np
import time
# 10.000~12.000秒のランダムな乱数を生成する
wait_time = float('{:.3f}'.format(np.random.rand()*2+10))
# 待つ
time.sleep(wait_time)BeautifulSoupと組み合わせる
実際では、クローリングをSelenium、スクレイピングをBeautifulSoupで行うことがほとんどです。
スクレイピングはelement.textでも出来るのですが、処理スピードが段違いなので…。
driver.page_sourceでWebページのソースコードを抜き出し、あとはBeautifulSoup側でスクレイピングの処理を行います。
from bs4 import BeautifulSoup
#
# 中略
#
# ソースコードを取得
html = driver.page_source
# HTMLをパースする
soup = BeautifulSoup(html, 'lxml') # または、'html.parser'
# CSSセレクタ
selector = '{{ CSSセレクタ }}'# テキスト
text = soup.select_one(selector).get_text()
# 属性値
attr = soup.select_one(selector).get('{{ 属性名 }}')# テキスト
texts = [i.get_text() for i in soup.select(selector)]
# 属性値
attrs = [i.get('{{ 属性名 }}') for i in soup.select(selector)] 【Python】静的なWebページを『Beautiful Soup』でスクレイピングする
【Python】静的なWebページを『Beautiful Soup』でスクレイピングする
tableをpandas.DataFrameに格納する
Seleniumでクローリング、BeautifulSuopでWebページのテーブルをスクレイピングした場合、それらのデータは一旦pandas.DataFrameに格納してから前処理することが多いと思います。
Webサイトによってtableの構成は様々だと思いますが、80%くらい以下のプログラムで取得できます。1発で取得格納出来なかった場合は、正規表現部分を都度変更して下さい。
import re
from bs4 import BeautifulSoup
import pandas as pd
#
# 中略
#
# ソースコードを取得
html = driver.page_source
# HTMLをパースする
soup = BeautifulSoup(html, 'lxml') # または、'html.parser'
selector = '{{ tableのCSSセレクタ }}' + ' tr'
tr = soup.select(selector)
pattern1 = r'<t[h|d].*?>.*?</t[h|d]>' # tdまたはthタグに囲まれた要素を検索
pattern2 = r'''<(".*?"|'.*?'|[^'"])*?>''' # htmlタグを検索
# 1行目をDataFrameのヘッダーにする
columns = [re.sub(pattern2, '', s) for s in re.findall(pattern1, str(tr[0]))]
# 2行目以降をDataFrameのデータにする
data = [[re.sub(pattern2, '', s) for s in re.findall(pattern1, str(tr[i]))] for i in range(1, len(tr))]
# DataFrameを作成する
df = pd.DataFrame(data=data, columns=columns)ファイルの保存場所を変更する
# ファイルのデフォルトの保存先を変更する
driver.command_executor._commands['send_command'] = (
'POST',
'/session/$sessionId/chromium/send_command'
)
params = {
'cmd': 'Page.setDownloadBehavior',
'params': {
'behavior': 'allow',
'downloadPath': '{{ ファイルの保存先(絶対または相対パス) }}'
}
}
driver.execute('send_command', params=params)import os, shutil
FILE_DOWNLOAD_DIR = '{{ ファイルの保存先(絶対または相対パス) }}'
# ダウンロード専用フォルダをリセットする
shutil.rmtree(FILE_DOWNLOAD_DIR)
os.makedirs(FILE_DOWNLOAD_DIR, exist_ok=True)display:none;で隠された要素を表示する
driver.execute_scriptメソッドでJavaScriptを実行し、CSSプロパティのdisplay:none;を削除します。
# display:none;で隠された要素を表示する
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)
driver.execute_script('arguments[0].style.display="";', element)BASIC認証を突破する
# BASIC認証のID、PWとURLをセットする
ID = '{{ ID }}'
PW = '{{ PASSWORD }}'
URL = '{{ URL }}'
# BASIC認証用のURLを定義
url = '{}:{}@{}'.format(ID, PW, URL)
# BASIC認証を突破する
driver.get(url)2段階認証を突破する
 Python+Seleniumで2段階認証(6桁のパスコード)を突破する全手順
Python+Seleniumで2段階認証(6桁のパスコード)を突破する全手順
reCAPTCHAを突破する
 【2Captcha】Python+Seleniumで『reCAPTCHA』を突破する方法
【2Captcha】Python+Seleniumで『reCAPTCHA』を突破する方法
定期実行
ローカルで定期実行する
 【保存版】cronでPython3を定時実行する方法&注意すべき4つのポイント
【保存版】cronでPython3を定時実行する方法&注意すべき4つのポイント
【おすすめ】サーバー(Heroku)で定期実行する
 スクレイピング(Selenium, Beautiful Soup)をサーバー上(Heroku)で定期実行させる方法
スクレイピング(Selenium, Beautiful Soup)をサーバー上(Heroku)で定期実行させる方法
【おまけ】Seleniumの雛形
記事の最後に、普段私がSeleniumのプログラムで使っているプロトタイプを紹介します。
import os, shutil, re, json
from glob import glob
import time
from datetime import datetime, timedelta
import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.alert import Alert
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
# Jupyter Notebookで全カラムを表示させる
pd.set_option('display.max_columns', None)
"""
初期設定
"""
#
# 定数定義
#
DRIVER_PATH = '{{ ローカルに保存したchromeドライバーのパス }}'
# DRIVER_PATH = '/app/.chromedriver/bin/chromedriver' # Heroku
FILE_DOWNLOAD_DIR = '{{ ファイルをダウンロードするダウンロード先のディレクトリ }}'
# 環境変数を使う場合(例:Slackに投稿する)
SLACK_ACCESS_TOKEN = os.environ['{{ 環境変数 }}']
CHANNEL_ID = '{{ チャンネルID }}'
#
# Seleniumをあらゆる環境で起動させるオプション
#
options = Options()
options.add_argument('--disable-gpu');
options.add_argument('--disable-extensions');
options.add_argument('--proxy-server="direct://"');
options.add_argument('--proxy-bypass-list=*');
options.add_argument('--start-maximized');
# options.add_argument('--headless'); # ※ヘッドレスモードを使用する場合、コメントアウトを外す
#
# Chromeドライバーの起動とオプション
#
driver = webdriver.Chrome(executable_path=DRIVER_PATH, chrome_options=options)
# 要素が見つからないときの暗黙的な待機処理
driver.implicitly_wait(10)
# ファイルのデフォルトの保存先を変更する
driver.command_executor._commands['send_command'] = (
'POST',
'/session/$sessionId/chromium/send_command'
)
params = {
'cmd': 'Page.setDownloadBehavior',
'params': {
'behavior': 'allow',
'downloadPath': FILE_DOWNLOAD_DIR
}
}
driver.execute('send_command', params=params)
#
# ダウンロード専用フォルダをリセットする
#
shutil.rmtree(FILE_DOWNLOAD_DIR)
os.makedirs(FILE_DOWNLOAD_DIR, exist_ok=True)
"""
クローリング/スクレイピング
"""
# Googleにアクセスする
url = '{{ URL }}'
driver.get(url)
# 処理1(テキストの入力)
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)
element.send_keys('{{ 入力するテキスト }}')
# 処理2(クリック)
selector = '{{ CSSセレクタ }}'
element = driver.find_element_by_css_selector(selector)
element.click()
# ︙
# ブラウザを終了する(全てのウィンドウを閉じる)
# Chromeのショートカットキー(Command+Q)と同じ動作
driver.quit()
# ︙
"""
Slackに投稿する
"""
url = 'https://slack.com/api/chat.postMessage'
params = {
'token': SLACK_ACCESS_TOKEN,
'channel': CHANNEL_ID,
'text': '{{ 投稿するテキスト }}',
'username': '{{ Botの名前 }}',
'icon_emoji': '{{ Botのアイコン }}',
}
response = requests.post(url, params=params)
data = response.json()
