ログインが不要なWebサイトをスクレイピングしたい場合は、Pythonのサードパーティ製のモジュール『Beautiful Soup』を使うと簡単です。
pip install beautifulsoup4Beautiful Soupは、Webページのソースコードの中から、お目当ての情報を『CSSセレクタ』や『その他の方法』を使って抽出するモジュールです。
そこで今回は、より実践的なBeautiful Soupの使い方を紹介します!
目次

データサイエンティスト / ブロガー
たぬ
tanu
福岡在住のデータサイエンティスト。Pythonでルーチンワークを瞬殺する仕組みを作ることやデータを視覚化することが得意です。
Beautiful Soupの使い方
Beautiful Soupは、HTMLやXMLから狙ったデータを抽出するためのモジュールです。
つまり、予めHTMLやXMLのソースコードを何らかの手段で用意しなければいけません。
そこで、Pythonのサードパーティ製のモジュールのrequestsを使用して、WebページのURLからソースコードを取得します。
pip install requestsrequestsで行い、HTMLのパース処理をBeautiful Soupで行います。import requests
from bs4 import BeautifulSoup
url = '{{ スクレイピングするURL }}'
r = requests.get(url)
soup = BeautifulSoup(r.content, 'lxml') # または、'html.parser'スクレイピングしたいWebページのソースコードが以下のような構成だったら
<!doctype html>
<html>
<body>
<div id="color">
<p>色</p>
<p class="r">あか</p>
<p class="g">みどり</p>
<div>
<p class="b1 b"><a href="http://sample.com/">ぐんじょう</a></p>
<p class="b2 b">つゆくさ</p>
<p class="b3 b">さびあさぎ</p>
</div>
</div>
</body>
</html>Beautiful Soupとrequestsを組み合わせたプログラムを実行すると変数soupには、以下のようにページ全体のソースコードが格納されるようになります。
print(soup)
# <!DOCTYPE doctype html>
#
# <html>
# <body>
# <div id="color">
# <p>色</p>
# <p class="r">あか</p>
# <p class="g">みどり</p>
# <div>
# <p class="b1 b"><a href="http://sample.com/">ぐんじょう</a></p>
# <p class="b2 b">つゆくさ</p>
# <p class="b3 b">さびあさぎ</p>
# </div>
# </div>
# </body>
# </html>要素を取得する
Beautiful Soupのチュートリアルや色んなサンプルを見てると、この記事では紹介していないfind_xxx系のメソッドがよく使われていますが、私の経験上ではCSSセレクタを使って抽出する場面がほとんどです。
CSSセレクタを使って要素を取得したい場合、複数の要素を取得する場合はselectメソッド、1つだけ取得する場合はselect_oneメソッドを使用します。
soup.select('CSSセレクタ', limit=None) # 戻り値:複数(リスト)
soup.select_one('CSSセレクタ') # 戻り値:1つ(文字列)soup.select('.b')
# [<p class="b1 b"><a href="http://sample.com/">ぐんじょう</a></p>, <p class="b2 b">つゆくさ</p>, <p class="b3 b">さびあさぎ</p>]
# type:list
soup.select_one('.b')
# <p class="b1 b"><a href="http://sample.com/">ぐんじょう</a></p>
# type:strテキストを取得する
要素が取得できたら、そのままget_textメソッドを使用してテキストを取得することができます。
soup.select_one('.b1').get_text()
# ぐんじょうただし、get_textメソッドは、listに対して使うことが出来ません。
soup.select('.b').get_text()
# AttributeError: 'list' object has no attribute 'get_text'リストからまとめてテキストを取得したい場合は、リスト内包表記を使用します。
[i.get_text() for i in soup.select('.b')]
# ['ぐんじょう', 'つゆくさ', 'さびあさぎ']属性の値を取得する
テキストの場合と同様に、要素が取得できたら、そのままgetメソッドを使用して属性の値を取得することができます。getメソッドには、属性名を指定します。
soup.select_one('.b a').get('href')
# http://sample.com/getメソッドもget_textメソッド同様に、listに対して使うことが出来ません。
soup.select('.b').get('class')
# AttributeError: 'list' object has no attribute 'get'リストからまとめて属性値を取得したい場合は、リスト内包表記を使用します。
[i.get('href') for i in soup.select('.b a')]
# ['http://sample.com/']
[i.get('class') for i in soup.select('.b')]
# [['b1', 'b'], ['b2', 'b'], ['b3', 'b']]
[i.get('class') for i in soup.select('p')]
# [None, ['r'], ['g'], ['b1', 'b'], ['b2', 'b'], ['b3', 'b']]実践編
この章では、実際のwebページからBeautiful Soupを使用して、スクレイピングしてみます。
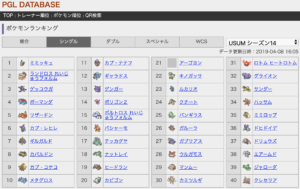
http://pgl-db.net/season-pokemon/?battle=1
例として、ポケモンの対戦でよく使われている上位30位までスクレイピングしてみます。
⌘+shift+iでGoogle Chromeのディベロッパーツールを起動します。
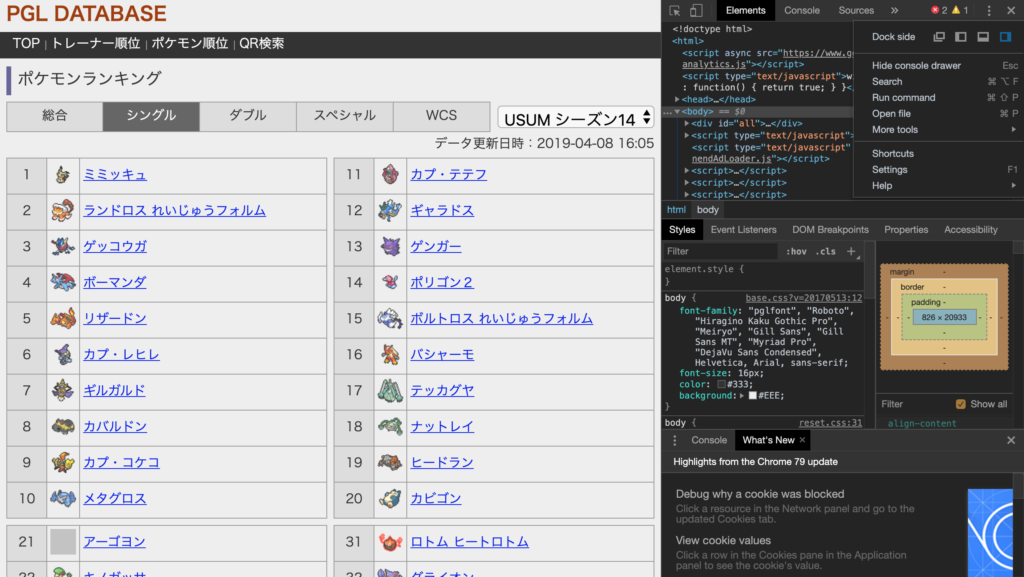
ディベロッパーツールの使い方は割愛します。
<div>
<div>
<table>
<tbody>
<tr>
<th>1</th>
<td><img src=""></td>
<td><a href="">ミミッキュ</a></td>
</tr>
︙省略
<tr>
<th>10</th>
<td><img src=""></td>
<td><a href="">メタグロス</a></td>
</tr>
</tbody>
</table>
</div>
<div>
<table>
<tbody>
<tr>
<th>11</th>
<td><img src=""></td>
<td><a href="">カプ・テテフ</a></td>
</tr>
︙省略
<tr>
<th>20</th>
<td><img src=""></td>
<td><a href="">カビゴン</a></td>
</tr>
</tbody>
</table>
</div>
︙省略
</div>ざっーとHTMLのソースコードを確認します。
今回スクレイピングするデータは、table要素のtr要素の3番目のtd要素であることが分かりますね。
つまり、求めたいCSSセレクタは、table tr td:nth-child(3)になります。
import requests
from bs4 import BeautifulSoup
url = 'http://pgl-db.net/season-pokemon/?battle=1'
r = requests.get(url)
soup = BeautifulSoup(r.content, 'lxml') # または、'html.parser'
print([i.get_text() for i in soup.select('table tr td:nth-child(3)', limit=20)])
# ['ミミッキュ', 'ランドロス れいじゅうフォルム', 'ゲッコウガ', 'ボーマンダ', 'リザードン', 'カプ・レヒレ', 'ギルガルド', 'カバルドン', 'カプ・コケコ', 'メタグロス', 'カプ・テテフ', 'ギャラドス', 'ゲンガー', 'ポリゴン2', 'ボルトロス れいじゅうフォルム', 'バシャーモ', 'テッカグヤ', 'ナットレイ', 'ヒードラン', 'カビゴン']目的のデータが取れましたね(^o^)
まとめ
静的なwebページのスクレイピングは、requestsでHTMLを取得し、Beautiful SoupでHTMLをパースします。
import requests
from bs4 import BeautifulSoup
url = '{{ スクレイピングするURL }}'
r = requests.get(url)
soup = BeautifulSoup(r.content, 'lxml') # または、'html.parser'要素は、複数の要素を取得する場合はselectメソッド、1つだけ取得する場合はselect_oneメソッドを使用し
soup.select('CSSセレクタ', limit=None) # 戻り値:複数(リスト)
soup.select_one('CSSセレクタ') # 戻り値:1つ(文字列)テキスト・属性の値は、それぞれget_textメソッド、getメソッドで取得します。
# テキスト
soup.select_one('CSSセレクタ').get_text()
# テキストのリスト
[i.get_text() for i in soup.select('CSSセレクタ')]# 属性値
soup.select_one('CSSセレクタ').get('属性名')
# 属性値のリスト
[i.get('属性名') for i in soup.select('CSSセレクタ')]連載:Pythonでクローリング/スクレイピング
《超実践的》Pythonでクローリング/スクレイピングを行うロードマップ
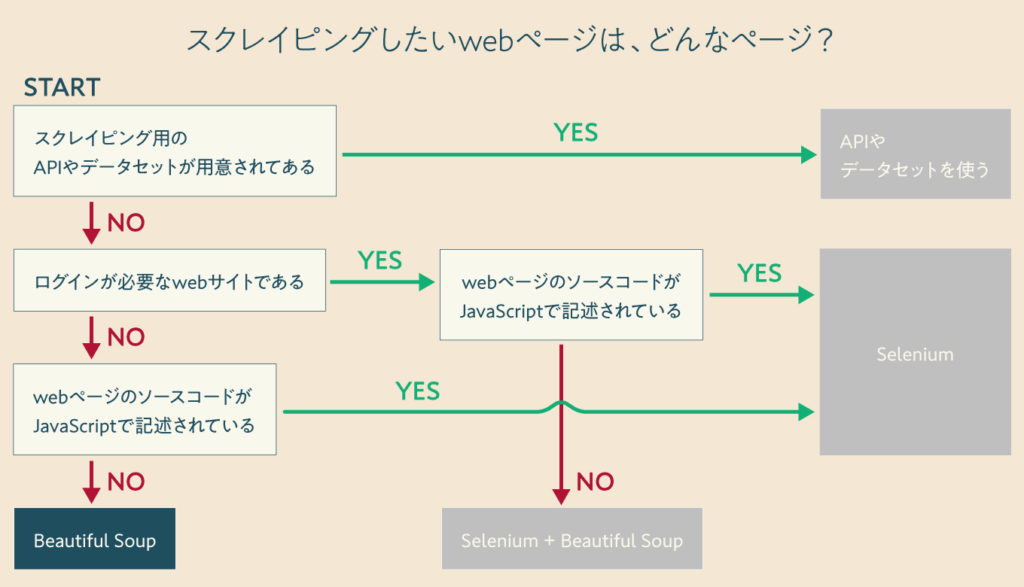
クローリングとスクレイピングをする前の事前準備・知識など- 静的なWebページを『Beautiful Soup』でスクレイピングする
ログインが必要なWebサイトを『Selenium』でクローリングし、『Beautiful Soup』でスクレイピングするJavaScriptで書かれたページを『Selenium』でスクレイピングするWeb APIやデータセットを使用してスクレイピングするスクレイピングで得たデータを様々な形式(pandas、BigQuery、スプレッドシート、DBなど)に変換するクローリング/スクレイピングをローカルマシンで定期実行する方法- クローリング/スクレイピングをサーバーで定期実行する方法
- クローリング/スクレイピングを安定させるための3つの設定(待機処理・エラーの通知・処理のリトライ)
クローリング/スクレイピングの次にやるべきこと
Selenium逆引きリファレンス
- Seleniumチートシート
【headlessモード】ブラウザを起ち上げずにSeleniumを実行する方法アラートダイアログを操作するセレクトボックスを選択する方法Basic認証を突破する方法- 2段階認証(6桁のパスコード)を突破する方法
- reCAPTCHAを突破する方法
- 【target="_blank"対策】driverを別ウィンドウに切り替える方法
【display:none対策】JavaScriptを実行して隠された要素を表示させる方法【表示読み込み対策】時間を遅延させるBeautiful Soupと組み合わせるherokuで定期実行させる手順

