
こんにちは、いろんな効率化が大好きなたぬ(@tanuhack)です!
Webに携わる仕事をしている以上、どんなキーワードでどんな記事が上位表示されているのか気になりませんか?
通常であれば、上のようなやり方で調べざるを得ませんが、スクレイピングすればパソコンが勝手に情報を集めてくれるようになるんですよ!!
今回はPythonを使って、Googleの検索結果をスクレイピングしてスプレッドシートに保存する方法を紹介します。
[aside]Pythonのインストールがまだ終わってない人は、こちらを参考にインストールしてみて下さい! [Mac]未経験者向け!Pythonの『導入・初期設定』から『実行』まで紹介
[/aside]
[Mac]未経験者向け!Pythonの『導入・初期設定』から『実行』まで紹介
[/aside]
目次

データサイエンティスト / ブロガー
たぬ
tanu
福岡在住のデータサイエンティスト。Pythonでルーチンワークを瞬殺する仕組みを作ることやデータを視覚化することが得意です。
本日のゴール
Pythonを使ってGoogleの検索結果(タイトル、要約文、キーワード、URL)をスクレイピングして、それぞれをスプレッドシートに記入させる
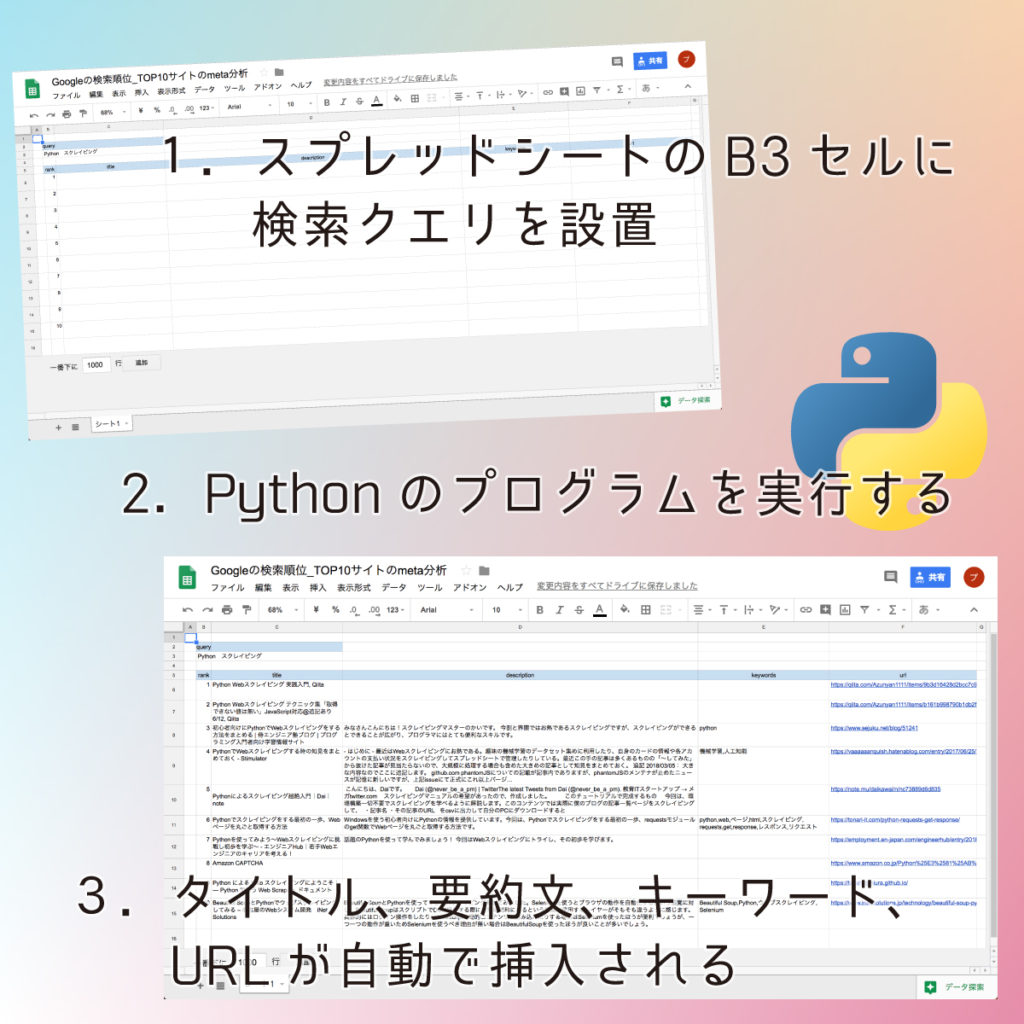
※雛形のスプレッドシートは後ほど共有します。
準備
- Python3.X系のインストール
- requestsライブラリのインストール
- lxmlライブラリのインストール
- cssselectライブラリのインストール
- 書き込むスプレッドシートを用意←コピーして使って下さい
- Pythonからスプレッドシートにアクセスする認証設定(※10分程度で終わります)
$ brew install python3
$ pip install requests
$ pip install lxml
$ pip install cssselect
 【もう迷わない】Pythonでスプレッドシートに読み書きする初期設定まとめ
【もう迷わない】Pythonでスプレッドシートに読み書きする初期設定まとめ
一応、下に自分の動作環境を載せておきます。
- macOS High Sierra 10.13.6
- Python 3.6.5
Macでやっていますが、もちろんWindowsでも実行可能です。しかし、その場合コマンドが若干違うので、そのへんは適宜調べて下さい。
それでは始めます。
各ライブラリの解説
スクレイピングのプログラムに移る前に、今回用いた3つのライブラリについて解説します。
よりスクレイピングに対しての理解が深まると思うので、参考程度に聞き流してください。
requestsライブラリ
Pythonには『urllib』というWebページを取得する標準ライブラリが用意されています。
ですが、少しばかり手間なので、もっとWebページを取得するのに長けた強力なサードパーティの『requestsライブラリ』を使用しました。
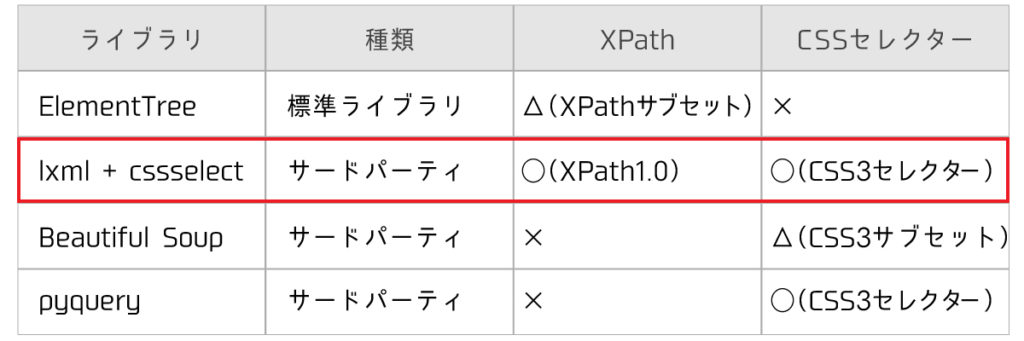
lxml、cssselectライブラリ
requestsで取得したHTMLから簡単にスクレイピングするために『lxml』ライブラリを使用しました。
他にも『Beautiful Soup』や『pyquery』といったスクレイピング専用のライブラリもありますが、高速に動作するlxmlの方に軍配が上がります。(※特にスクレイピングは、重たい処理なので)
lxmlとcssselectを組み合わせると、CSSセレクタを指定してHTMLの要素を直接指定することができます。
普段からCSSに慣れ親しんでいる私にとって好都合でした。
gspreadライブラリ
Python3.Xでスプレッドシートを操作することができるライブラリです。
ワークシートのセルの値を取得したり、更新したりと他にもプログラム次第でPythonから色々操作できます。
注意点としては、リクエスト回数が100秒間に100回と制限が設けられているところです。
なので、スプレッドシートに書き出す際は、なるべくまとまったデータを送るように心掛けましょう。
[aside]gspreadの詳しい使い方詳しい使い方は過去記事にまとめているので良かったら参考にして下さい。
 gspreadライブラリの使い方まとめ!Pythonでスプレッドシートを操作する
[/aside]
[aside]gspreadを高速に使いたい方やAPI回数の呼び出す回数を減らしたい方はこちらの記事を参考にして下さい。
gspreadライブラリの使い方まとめ!Pythonでスプレッドシートを操作する
[/aside]
[aside]gspreadを高速に使いたい方やAPI回数の呼び出す回数を減らしたい方はこちらの記事を参考にして下さい。 [データI/O]スプレッドシート×DataFrameを一気に変換する方法
[/aside]
[データI/O]スプレッドシート×DataFrameを一気に変換する方法
[/aside]
アルゴリズム
ここでは、実際にプログラムを書く上で、こんなフローにすれば良さそうだなと思った、大まかなアルゴリズムを記載します。
- 必要なライブラリをインポートする
- スプレッドシートAPIと認証設定する
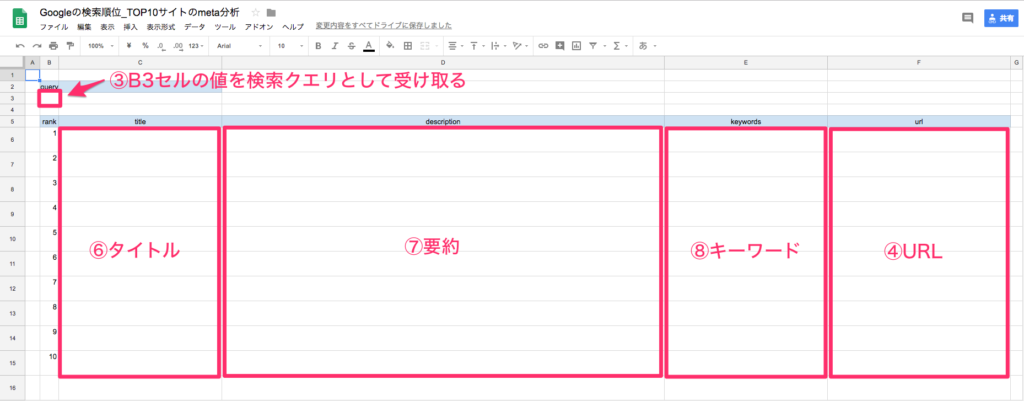
- スプレッドシートのB3セルに記入している値を検索クエリとして変数に格納
- Googleの検索結果画面(10位まで)の情報を抜き出し、サイトのURLをスプレッドシートのF列に順に記入する
- F列に入力されているURLを順にたどっていき、タイトル、要約文、キーワードを抜き出す。
- C列にタイトルを記入する
- D列に要約文を記入する
- E列にキーワードを記入する
プログラム
以下、Google自然検索のTop10位サイトにおけるタイトルと要約、キーワードを抜き出してスプレッドシートに入力するPythonのプログラムです。
クレデンシャルの秘密キーと用意したスプレッドシートキー以外はコピペで動作すると思います。
import re
import json
import requests as rq
import lxml.html as lx
import gspread
from oauth2client.service_account import ServiceAccountCredentials
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name('クレデンシャルの秘密キー', scope)
gc = gspread.authorize(credentials)
#用意したスプレッドシートキーを指定する
SPREADSHEET_KEY = 'スプレッドシートキー'
worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1
#B3セルの値を検索クエリとして受け取る
search_query=worksheet.acell('B3').value
#requestsのget関数を使用して、Googleの検索結果画面(10位まで)の情報を抜き出す
r = rq.get('http://www.google.co.jp/search?hl=jp&gl=JP&num=10&q='+search_query)
html = r.text.encode() #コンテンツをエンコードする
root = lx.fromstring(html) #パース(lxmlでスクレイピングする準備をする)
#F6セルから下方向に記事URLを抜き出す
i=6
for a in root.cssselect('div#search h3.r a'):
worksheet.update_cell(i,6, re.sub(r'/url\?q=|&sa.*', '',a.get('href'))) #update_cell(行,列,上書きする値)
i = i+1
#F列に入力されているURLをクロールして、タイトル、要約、キーワードを抜き出す
#10位のサイトまで繰り替えす
for i in range(6,16):
try: # 古いサイトが読み込めないので無視する
search = rq.get(worksheet.acell('F'+str(i)).value) #acell('F6'.value) F6〜15セルの値をクロールする
search_html = search.text.encode(search.encoding) #encode(XXXX.encoding):読み込む前に文字化けするものに対応
#文字コードがUTFー8ならUTF-8でデコードしてパース
if(search.encoding=='utf-8' or search.encoding=='UTF-8'):
search_root = lx.fromstring(search_html.decode('utf-8'))
#文字コードがそれ以外は普通にパース
else:
search_root = lx.fromstring(search_html)
#タイトルの設定
list_title = []
for a in search_root.cssselect('title'):
list_title.append(a.text)
title=''
for index,item in enumerate(list_title):
if index==0:
title = item
else:
title = title + ', ' +item
worksheet.update_cell(i,3, title)
#ディスクリプションの設定
list_description = []
for a in search_root.cssselect('meta[name="description"]'):
list_description.append(a.get('content'))
description=''
for index,item in enumerate(list_description):
if index==0:
description = item
else:
description = description + ', ' +item
worksheet.update_cell(i,4, description)
#キーワードの設定
list_keywords = []
for a in search_root.cssselect('meta[name="keywords"]'):
list_keywords.append(a.get('content'))
keywords=''
for index,item in enumerate(list_keywords):
if index==0:
keywords = item
else:
keywords = keywords + ', ' +item
worksheet.update_cell(i,5, keywords)
except: #例外処理:古いサイトを読み込めなかったときにする処理
worksheet.update_cell(i,3, 'エラーのため測定不能')
worksheet.update_cell(i,4, 'エラーのため測定不能')
worksheet.update_cell(i,5, 'エラーのため測定不能')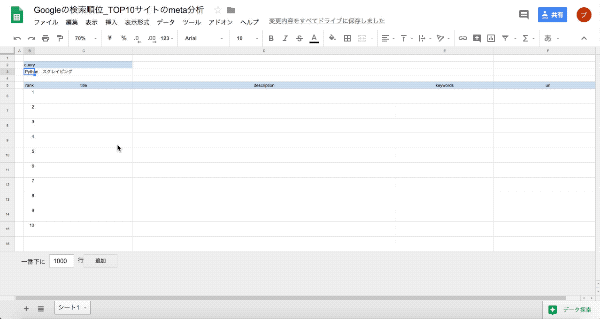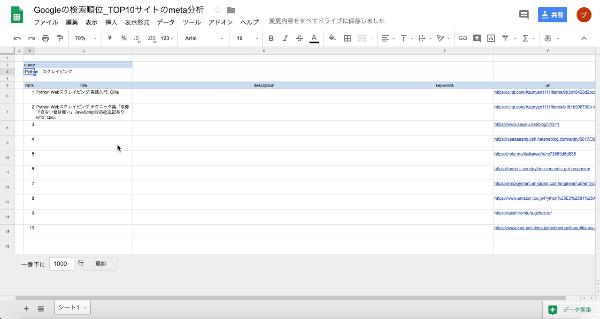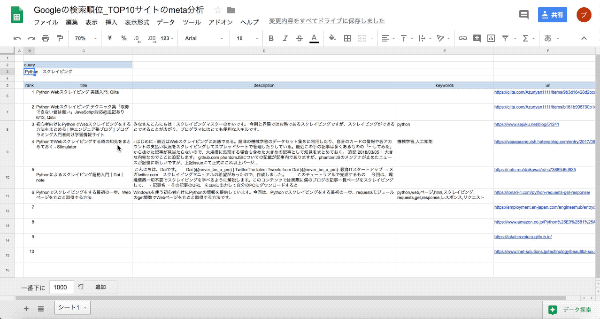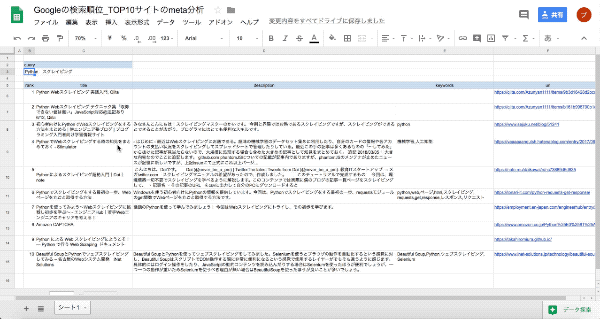
もっとスプレッドシートの出力をカスタマイズしたい場合は、gspreadライブラリを参考にすると良いですよ。
gspreadライブラリの使い方まとめ!Pythonでスプレッドシートを操作する
さいごに
今回はPythonを使って、Googleの検索結果をスクレイピングして、スプレッドシートに記入させるプログラムを紹介しました。
Webに携わる方であれば、結構嬉しいプログラムなのではないでしょうか。
[aside]スクレイピングを好きな時間に定時実行させたい欲張りさんは、この記事をどうぞ! 【保存版】cronでPython3を定時実行する方法&注意すべき4つのポイント
[/aside]
【保存版】cronでPython3を定時実行する方法&注意すべき4つのポイント
[/aside]
それでは、良いスクレイピングライフを



