
こんにちは、データサイエンティストのたぬ(@tanuhack)です!
データ分析の仕事をしていると、スプレッドシートの表をPandasのDataFrameに取り込んだり、DataFrameをスプレッドシートに出力したりしたくなりませんか?(私がそうです)
これは過去記事でも紹介したように、GoogleAPI(SheetAPI・DriveAPI)とgspreadモジュールを使えば、Pythonからスプレッドシートに読み書きすることができるようになります。
 【もう迷わない】Pythonでスプレッドシートに読み書きする初期設定まとめ
【もう迷わない】Pythonでスプレッドシートに読み書きする初期設定まとめ
 gspreadライブラリの使い方まとめ!Pythonでスプレッドシートを操作する
gspreadライブラリの使い方まとめ!Pythonでスプレッドシートを操作する
PythonとGoogleのアプリケーションを繋げるために必要なGoogleAPIには「100秒間に100回しかAPIを叩けない」という致命的な弱点が存在します。
2次元配列やDataFrameの値を1つずつセルに入力していると、一瞬で100回の制限を迎えてしまうことになりますね。
つまり、実用レベルで『Python×スプレッドシート』を実現させるためには、1回のAPI呼び出しだけでスプレッドシートの表全体をDataFrameに格納したり、DataFrameをスプレッドシートに出力させなければいけないという訳です。
[aside]補足APIの呼び出しが減ることで、プログラムの処理速度も速くなるというメリットもあります[/aside]
そこで今回は、1回のAPIの呼び出しだけでスプレッドシート×Python間のデータI/Oを実現させる方法を紹介します。
Pythonでスプレッドシートを操作するためには、他にもやらないといけない設定が10通りくらいあります。
過去記事でそのへんの流れを詳しく紹介しているので、よかったら参考にして下さい。かなり気合いれて書いてのでどうぞ!
【もう迷わない】Pythonでスプレッドシートに読み書きする初期設定まとめ
ということでここからは、スプレッドシート×Pythonの初期設定が終わっている前提で話を進めていきますね!
目次

データサイエンティスト / ブロガー
たぬ
tanu
福岡在住のデータサイエンティスト。Pythonでルーチンワークを瞬殺する仕組みを作ることやデータを視覚化することが得意です。
前提条件
まず前提として、以下のように『操作したいスプレッドシートのワークシートの選択』まで完了しているものとします。
import pandas as pd
import gspread
import json
from oauth2client.service_account import ServiceAccountCredentials
#2つのAPIを記述しないとリフレッシュトークンを3600秒毎に発行し続けなければならない
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
#認証情報設定
#ダウンロードしたjsonファイル名をクレデンシャル変数に設定(秘密鍵、Pythonファイルから読み込みしやすい位置に置く)
credentials = ServiceAccountCredentials.from_json_keyfile_name('秘密鍵のJSON', scope)
#OAuth2の資格情報を使用してGoogle APIにログインします。
gc = gspread.authorize(credentials)
#共有設定したスプレッドシートキーを変数[SPREADSHEET_KEY]に格納する。
SPREADSHEET_KEY = 'スプレッドシートキー'
#共有設定したスプレッドシートのワークシート1を開く
worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1スプレッドシートをDataFrameに取り込む
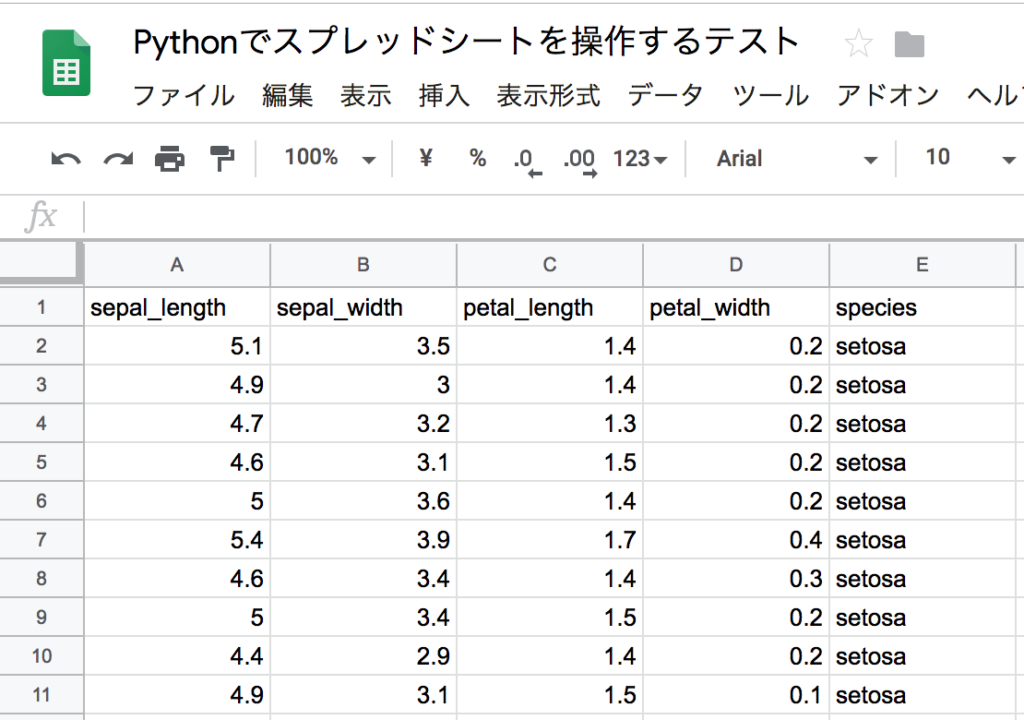
スプレッドシートの表をデータフレームに格納するためには、gspreadモジュールのget_all_values()を使います。
get_all_values()は、スプレッドシートの指定したワークシートの値をすべてstring型で格納するメソッドです。
get_all_values()
Returns a list of lists containing all cells’ values as strings.
df = pd.DataFrame(worksheet.get_all_values())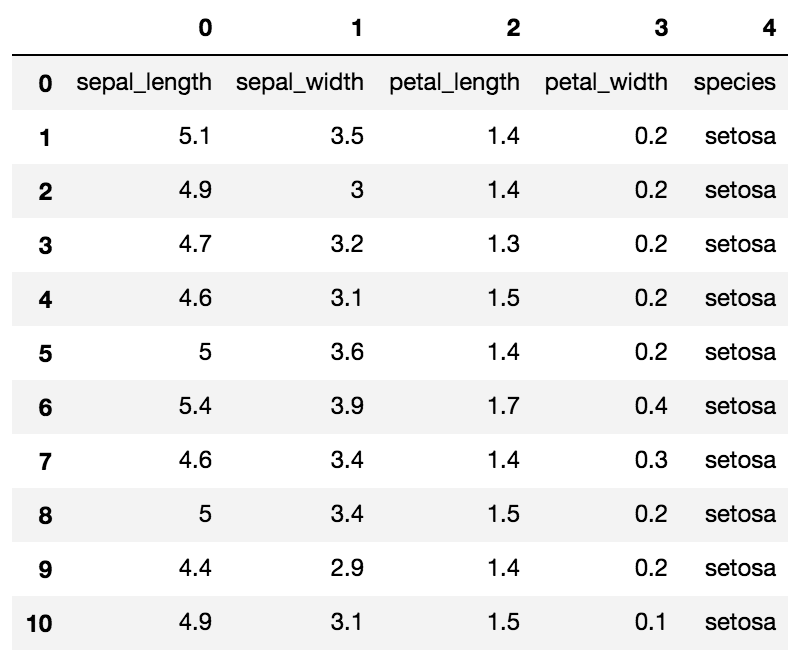
ただ、このままだとカラム名が気持ち悪いので、修正します。
df = pd.DataFrame(worksheet.get_all_values())
df.columns = list(df.loc[0, :])
df.drop(0, inplace=True)
df.reset_index(inplace=True)
df.drop('index', axis=1, inplace=True)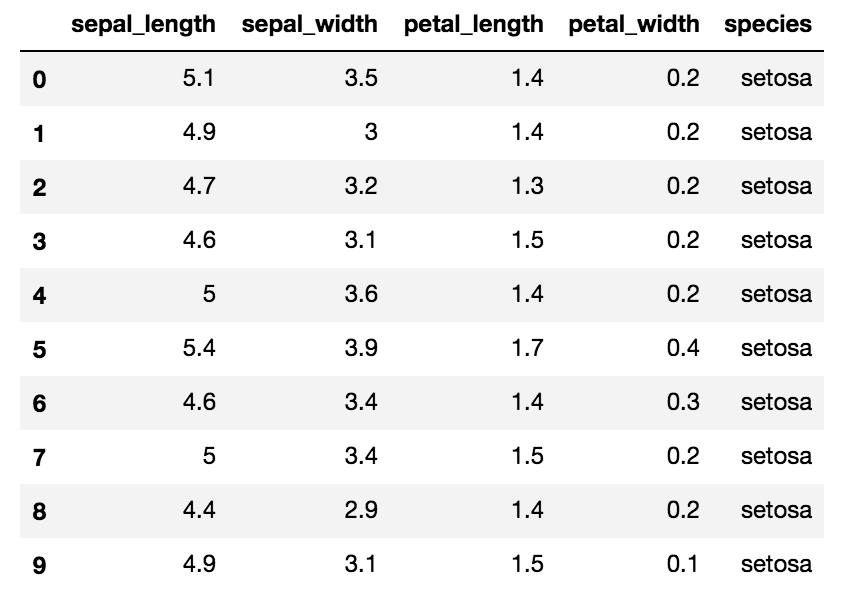
いい感じですね(^^)
DataFrameをスプレッドシートに書き出す
お次は、DataFrameをスプレッドシートに書き出す方法です。
今回は例として、Rでお馴染みの『アヤメの統計データ』をPandasのDataFrameに格納して、それをスプレッドシートに書き出すという処理をしてみようと思います。
統計データを用意するのが面倒だったので、描画ライブラリのseabornから読み込めるデータセットを用いました。
import seaborn as sns # ==> pip install seaborn
iris = sns.load_dataset('iris')
# type(iris) ==> pandas.core.frame.DataFrame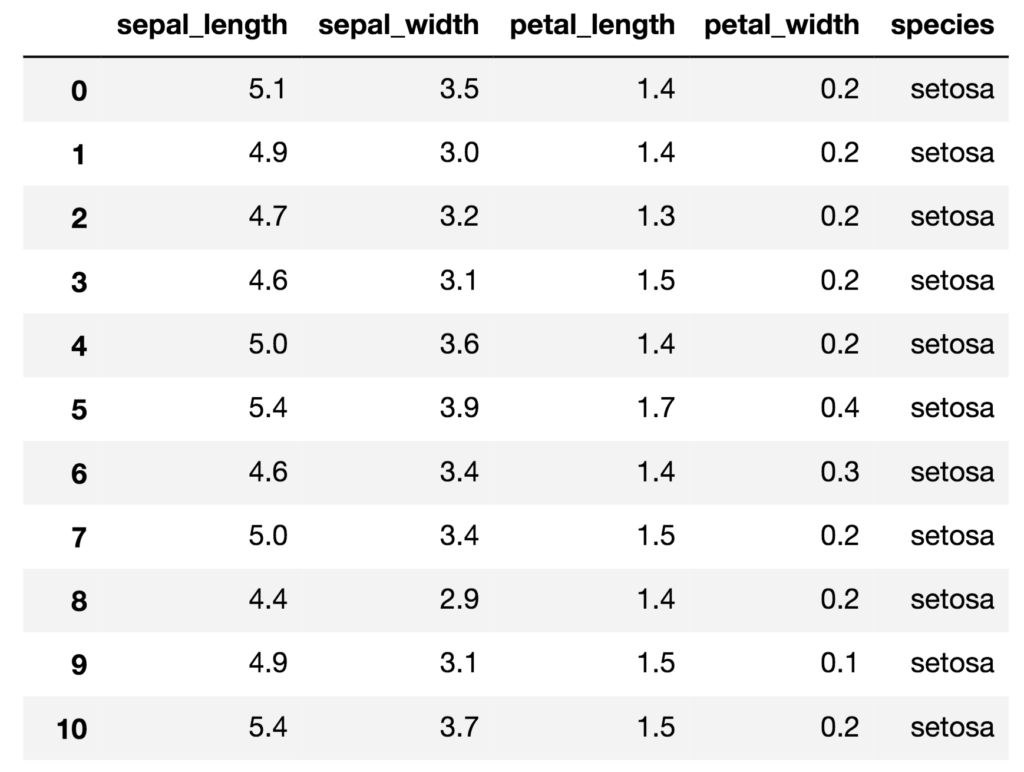
| レコード数 | 150 |
|---|---|
| カラム数 | 5 |
| カラム名 | 説明 | データの尺度名 |
|---|---|---|
| sepal_length | がく片の長さ:4.3~7.9(cm) | 間隔尺度(量的変量) |
| sepal_width | がく片の幅:2.0~4.4(cm) | 間隔尺度(量的変量) |
| petal_length | 花びらの長さ:1.3~6.9(cm) | 間隔尺度(量的変量) |
| petal_width | 花びらの幅:0.1~2.5(cm) | 間隔尺度(量的変量) |
| species | アヤメの種類(setosa, versicolor, virginica) | 名義尺度(質的変量) |
DataFrameを書き出す
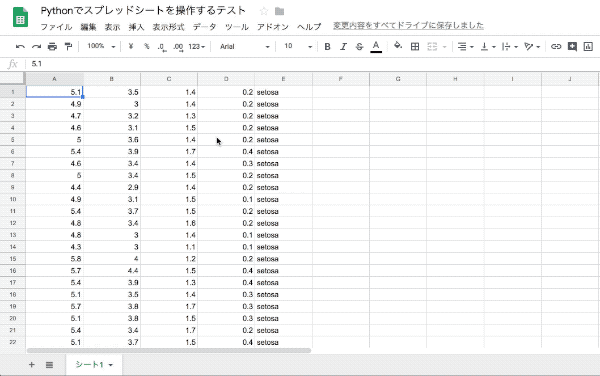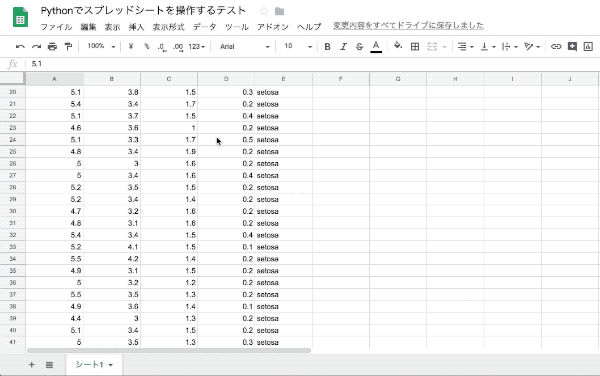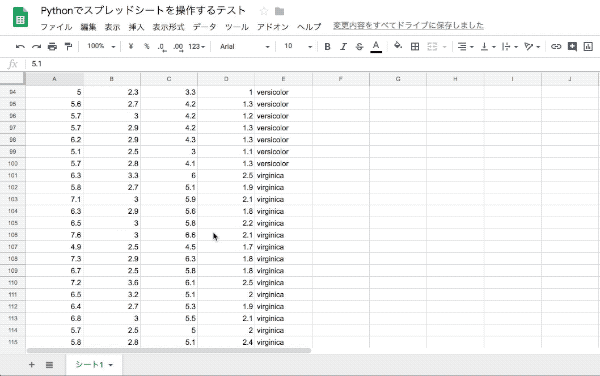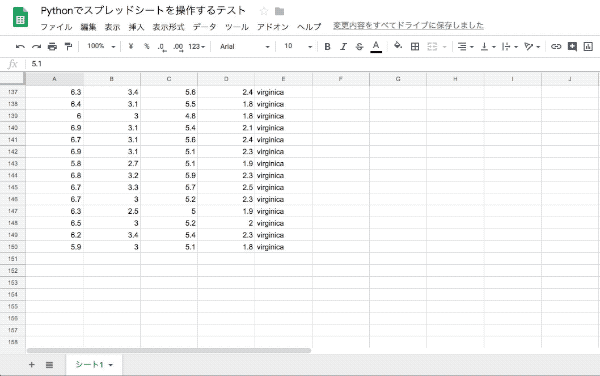
cell_list = worksheet.range('A1:E150')
for cell in cell_list:
val = iris.iloc[cell.row-1][cell.col-1]
cell.value = val
# スプレッドシートに書き出す
worksheet.update_cells(cell_list)このコードの鍵は3つあります。
| コマンド | 説明 |
|---|---|
cell_list = worksheet.range('A1:E150') |
貼り付けるスプレッドシートの範囲を指定する |
val = iris.iloc[cell.row-1][cell.col-1] |
DataFrameのilocでcell_listの番地([0][0]〜[149][4])にDataFrameの値を1つずつ順に格納する |
worksheet.update_cells(cell_list) |
スプレッドシートに複数の値を一気に貼り付ける |
今回は『150行5列のDataFrameをスプレッドシートに書き出す』という条件があったので、cell_list = worksheet.range('A1:E150')と設定出来ました。
しかし毎回毎回、行列数を調べてそれに対応させるのは大変だと思いませんか?
ということで、次はこのプログラムを改良して、可変長のDataFrameでも対応できるように設定してみます。
行と列が可変長のDataFrameを書き出す
# 数字からアルファベットを返す関数
# 例:26→Z、27→AA、10000→NTP
def toAlpha(num):
if num<=26:
return chr(64+num)
elif num%26==0:
return toAlpha(num//26-1)+chr(90)
else:
return toAlpha(num//26)+chr(64+num%26)
col_lastnum = len(iris.columns) # DataFrameの列数
row_lastnum = len(iris.index) # DataFrameの行数
cell_list = worksheet.range('A1:'+toAlpha(col_lastnum)+str(row_lastnum))
for cell in cell_list:
val = iris.iloc[cell.row-1][cell.col-1]
cell.value = val
worksheet.update_cells(cell_list) Pythonで数値とアルファベットを何桁でも相互変換する方法
Pythonで数値とアルファベットを何桁でも相互変換する方法
これで、元のDataFrameの大きさが変わっても、問題無くスプレッドシートに貼り付けられるようになりました。
ただ、このままだと、ヘッダー名やインデックス名が表示されていません。
次は、ヘッダー名やインデックス名も一緒にスプレッドシートに書き出す方法を紹介します。
DataFrameのヘッダー・インデックスも書き出す
ヘッダーと中身をスプレッドシートに書き出す
cell_list = worksheet.range('A1:'+toAlpha(col_lastnum)+str(row_lastnum+1))
for cell in cell_list:
if cell.row == 1:
val = iris.columns[cell.col-1]
else:
val = iris.iloc[cell.row-2][cell.col-1]
cell.value = val
worksheet.update_cells(cell_list)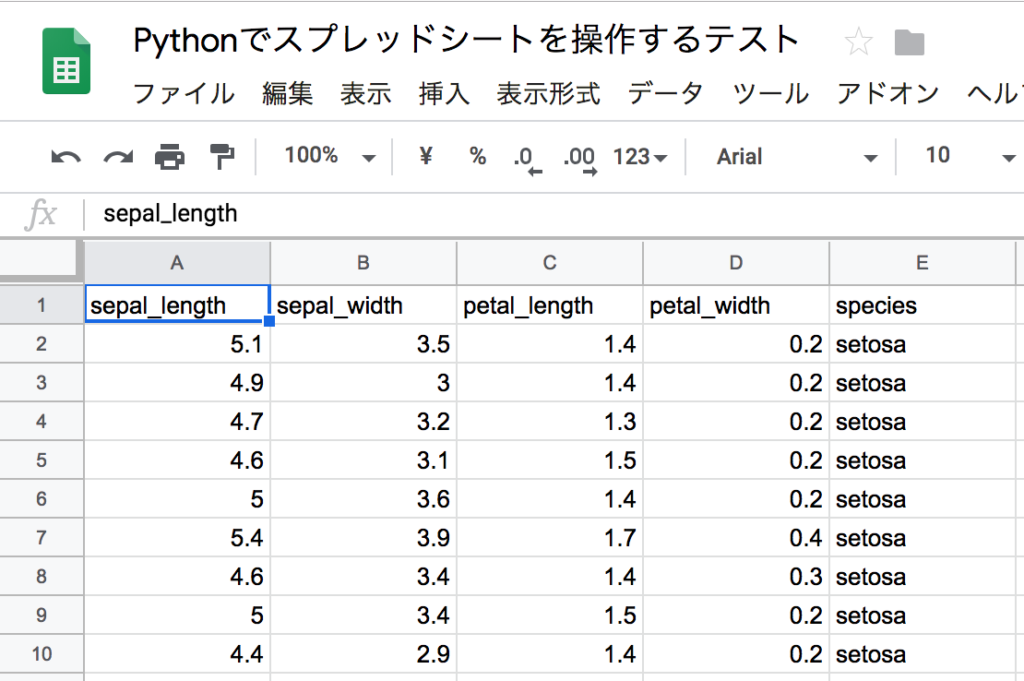
インデックスと中身をスプレッドシートに書き出す
cell_list = worksheet.range('A1:'+toAlpha(col_lastnum+1)+str(row_lastnum))
for cell in cell_list:
if cell.col == 1:
val = iris.index[cell.row-1]
else:
val = iris.iloc[cell.row-1][cell.col-2]
cell.value = val
worksheet.update_cells(cell_list)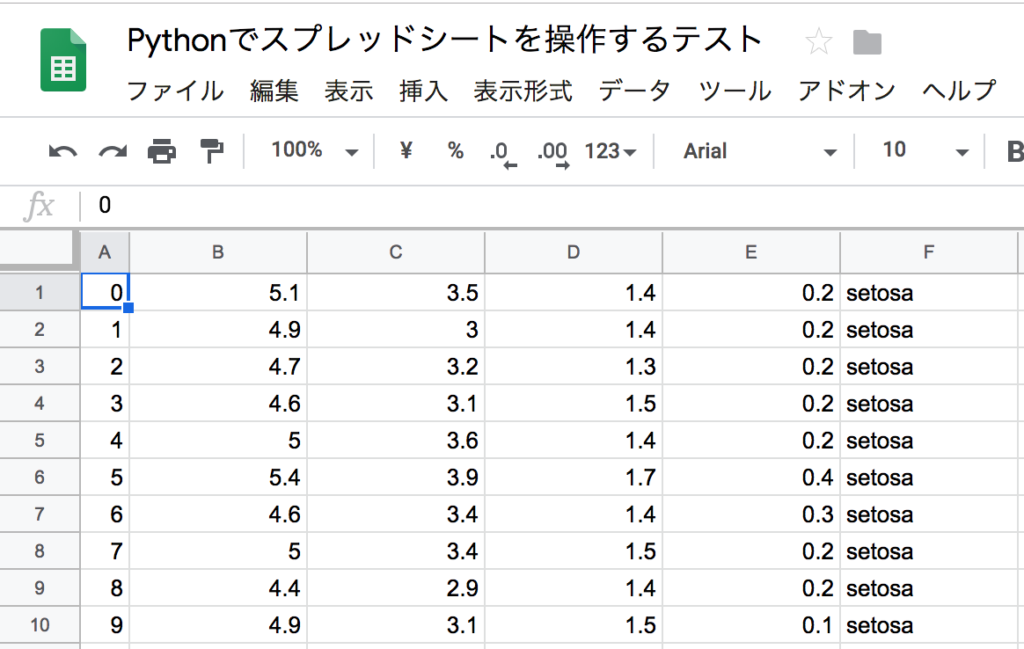
ヘッダーとインデックス、中身をスプレッドシートに書き出す
cell_list = worksheet.range('A1:'+toAlpha(col_lastnum+1)+str(row_lastnum+1))
for cell in cell_list:
if cell.col == 1 and cell.row == 1:
val = ''
elif cell.col == 1:
val = iris.index[cell.row-2]
elif cell.row == 1:
val = iris.columns[cell.col-2]
else:
val = iris.iloc[cell.row-2][cell.col-2]
cell.value = val
worksheet.update_cells(cell_list)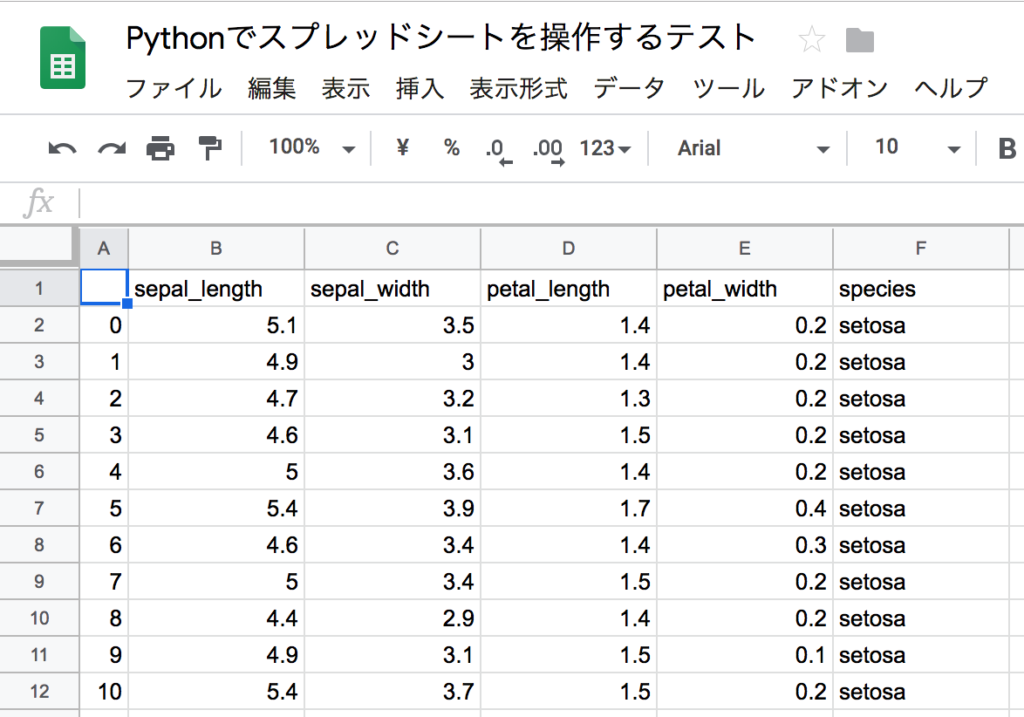
A1セル以外の場所から書き出す
いままで紹介したプログラムは全てA1セルから貼り付けていましたね。
場合によっては、A1セル以外にB2やC4セルからなど貼り付けたいこともあるでしょう。最後のそのプログラムを実現させます。
- 可変長DataFrame
- ヘッダーあり
- C4セルから貼り付け
import re
start_cell = 'C4' # 列はA〜Z列まで
start_cell_col = re.sub(r'[\d]', '', start_cell)
start_cell_row = int(re.sub(r'[\D]', '', start_cell))
# アルファベットから数字を返すラムダ式(A列~Z列まで)
# 例:A→1、Z→26
alpha2num = lambda c: ord(c) - ord('A') + 1
# 展開を開始するセルからA1セルの差分
row_diff = start_cell_row-1
col_diff = alpha2num(start_cell_col)-alpha2num('A')
# DataFrameのヘッダーと中身をスプレッドシートのC4セルから展開する
cell_list = worksheet.range(start_cell+':'+toAlpha(col_lastnum+col_diff)+str(row_lastnum+1+row_diff))
for cell in cell_list:
if cell.row == 1+row_diff:
val = iris.columns[cell.col-(1+col_diff)]
else:
val = iris.iloc[cell.row-(2+row_diff)][cell.col-(1+col_diff)]
cell.value = val
worksheet.update_cells(cell_list)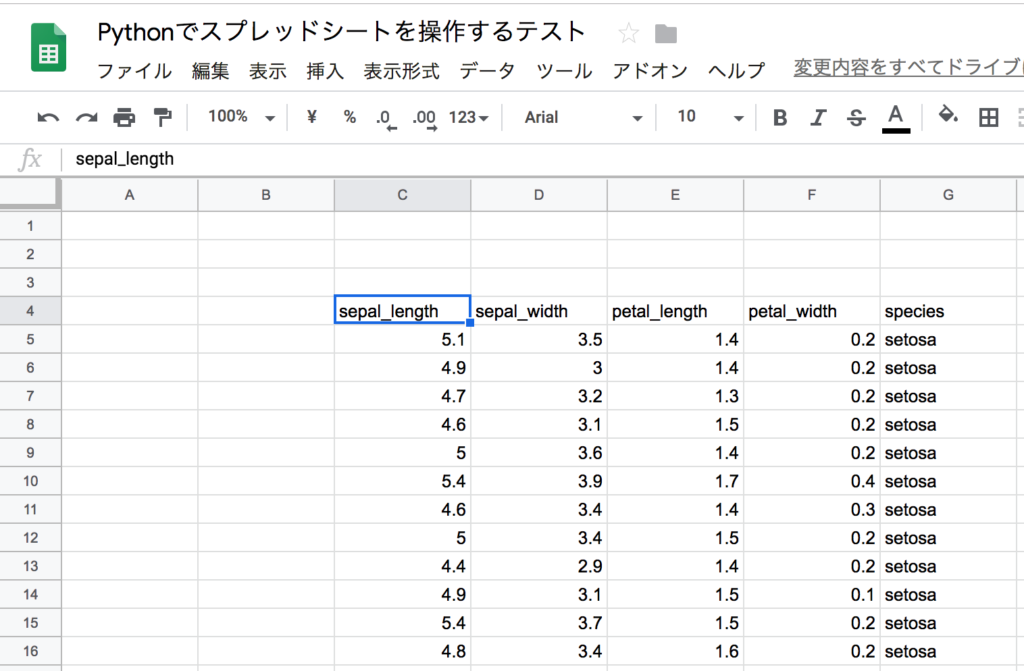
さいごに
今回は、スプレッドシート×Pythonの連携をより実務レベルで使うために欠かせない方法を紹介しました。
APIの呼び出し回数が減れば減るほど、プログラムは高速に動作します!!
それでは〜


