
こんにちは、色んな効率化が大好きなたぬ(@tanuhack)です!
普段スプレッドシートで文字列を操作するときってどんな関数使っていますか?
LEFT、MID、SUBSTITUTE関数あたりが一般的なんじゃないですかね。
今回紹介する文字列のウルトラな抽出方法は、正規表現という記号の組み合わせでテキストのパターンを表現できる記法を用います。
スプレッドシートであいまいな検索を行うときは『※』や『?』が用意されていますが、正規表現を覚えると目クソ鼻クソ同然です。
一度、正規表現を覚えると使っていなかったころに戻れなくなるくらい便利なので、この記事を参考にぜひマスターされてください!
この関数はEXCELにはありません。スプレッドシート独特の関数です。
目次

データサイエンティスト / ブロガー
たぬ
tanu
福岡在住のデータサイエンティスト。Pythonでルーチンワークを瞬殺する仕組みを作ることやデータを視覚化することが得意です。
正規表現って何?
正規表現とは、下の表にある記号を使って文字列のパターンを表現する記法のことです。
そっ閉じしたくなるくらい最初は訳分からないと思います。が、正規表現は、あなたがプログラマじゃない限り全てを覚える必要は全くありません。
必要になったときに適宜確認するみたいな使い方で全然OKなので、どうかここは堪えて最後まで読み進めてくださいね。
[aside]補足ここでは基本的な正規表現を紹介しています。もっと詳しく知りたい方はググってくださいね
[/aside]

基本のメタキャラクタ
任意の1文字や任意の半角数字などを指定することができます。
| . | 任意の1文字 |
|---|---|
| \w | 英単語を構成する文字(a~z,A~Z,_,1~9) |
| \W | 英単語を構成する文字以外 |
| \s | 空白文字(半角スペース,タブ,改行,キャリッジリターン) |
| \S | 空白文字以外 |
| \d | 半角数字(0~9) |
| \D | 半角数字以外 |
| \b | 単語の境界に一致 |
| [abc] | 指定された文字のどれかに一致(この場合abcのいずれかに一致) |
| [0-9] | マッチする文字の範囲を指定する表現(この場合0から9まで。他には[a-z][A-Z]など文字コードが連続していれば使える。) |
| (pattern1|pattern2) | 指定されたパターンのどれかにマッチする表現 |
量指定子
量指定子は、文字の後ろに配置し、前の文字が何回出てくるのかを指定します。
| * | 0回以上の繰り返しにマッチ |
|---|---|
| + | 1回以上の繰り返しにマッチ |
| {n} | n回の繰り返しにマッチする表現 |
| {n,} | n回以上の繰り返しにマッチする表現 |
| {n,m} | n回以上m回以下の繰り返しにマッチする表現 |
| ? | 0回または1回の出現にマッチする表現 |
アンカー
文字列の先頭や末尾に特定の文字がある文字列も表現できます。
| ^✕✕✕ | 文字列の先頭に✕✕✕がある文字列に一致 |
|---|---|
| ✕✕✕$ | 文字列の末尾に✕✕✕がある文字列に一致 |
正規表現まとめ
今紹介したものを使うと、都道府県は次のように表わせます。
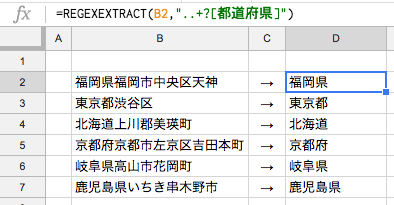
STEP1:[都道府県]
正規表現の基本のメタキャラクタを利用します。
| [abc] | 指定された文字のどれかに一致(この場合abcのいずれかに一致) |
|---|
これで、文字列の中の都道府県を抜き出すことができます。
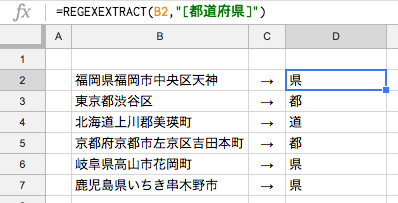
STEP2:..+[都道府県]
まず日本の都道府県の文字列の仕組みを考えます。
日本の都道府県は、〇〇府や〇〇〇県といったように、『ある2〜3文字+都道府県』を連結させた文字列ですね。
なので正規表現では『..+』が当てはまります。
| . | 任意の1文字 |
|---|---|
| + | 1回以上の繰り返しにマッチ |
『.』の後に『+』を置くことで任意の2〜3文字が実現出来ます。
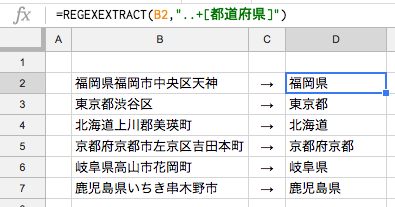
それっぽくなってきましたね。
でも、このままだと京都が2回連続で表示されているので、これを1回に抑えてあげる必要があります。
STEP3:..+?[都道府県]
正規表現の『?』を使って、繰り返しを0回または1回にします。
| ? | 0回または1回の出現にマッチする表現 |
|---|
これで完成です♪
正規表現が使える関数
前の章でしれっと関数使っていましたが、この章ではスプレッドシートで正規表現が使える関数を全3つ紹介します。
REGEXEXTRACT
先程の都道府県の関数は、このREGEXEXTRACTを使っていました。
用意した文字列の中から、正規表現で表した文字列を取りだすだけの関数なので手っ取り早く使えるはずです!
1つ簡単な例を紹介してみます♪
=12
REGEXREPLACE
個人的にREGEXEXTRACT関数よりも使いやすいです。
正規表現でヒットした文字列を空白や任意の文字に即座に置換できるのが便利ですね。
1つ簡単な例を紹介してみます♪
=SSabcSSSS
REGEXMATCH
IF文の条件分岐で使うことが多いです。
普通IF文で複数の条件分岐を実現させたい場合はIF文の中にIF文をネストさせてあげる必要がありますが、正規表現の『|』をつかうと回避できる場合があります。
| (pattern1|pattern2) | 指定されたパターンのどれかにマッチする表現 |
|---|
この関数もめっちゃ便利なので、ぜひ存在を覚えておいてくださいね。
(※検索対象文字列に検索する文字列が含まれている場合『TRUE』を返す。含まれていない場合は『FALSE』を返す。)
1つ簡単な例を紹介してみます♪
=TRUE
まとめ
今回は正規表現を使ってスプレッドシートの文字列を抽出できる方法と正規表現に対応している関数を3つ紹介させて頂きました。
僕も正規表現自体そんなに詳しくはありませんが、調べて使う分には何も困っていません。
プログラマじゃないんだし、正規表現そのものを覚える必要は本当にないと思います。
しかし正規表現を使えるのと使えないのでは、スプレッドシートを使った仕事のスピードが明らかに違うので、正規表現の使い方だけでもマスターして周りと差を付けてくださいね(^o^)

