ググることが多かったPythonの文法を自分用にまとめました。
目次
変数
代入する
構文
変数 = 値val = 10
print(val)
# 10val1, val2, val3 = 10, 100, 1000
print(val1, val2, val3)
# 10 100 1000val1 = val2 = val3 = 0
print(val1, val2, val3)
# 0 0 0val1 = 10
val2 = 100
val1, val2 = val2, val1
print(va11, val2)
# 100 10型
Pythonの組み込み型のtypeメソッドを使って、変数のデータ型を調べます。
制御構文
条件分岐
構文
if 条件式1:
# 条件式1がTrueのときに行う処理
elif 条件式2:
# 条件式1がFalseで条件式2がTrueのときに行う処理
elif 条件式3:
# 条件式1, 2がFalseで条件式3がTrueのときに行う処理
︙
else:
# すべての条件式がFalseのときに行う処理n = 35
if n%15 == 0:
print('FizzBuzz')
elif n%3 == 0:
print('Fizz')
elif n%5 == 0:
print('Buzz')
else:
print(n)
# Buzz組み込み型のboolメソッドで、値がif文の条件式のときにTrueになるかFalseになるか確認できます。
if文の条件式でTrueになるもの
print(bool(10)) # True
print(bool('a')) # True
print(bool(['a'])) # True
print(bool({'a': 100})) # True
print(bool('False')) # Trueif文の条件式でFalseになるもの
print(bool(0)) # False
print(bool(0.0)) # False
print(bool('')) # False
print(bool([])) # False
print(bool({})) # False
print(bool(None)) # False構文
変数 = 条件が真のときの値 if 条件式 else 条件が偽のときの値if-else句
n = 5
if n%3 == 0:
result = 'OK'
else:
result = 'NG'
print(result)
# NG三項演算子
n = 5
result = 'OK' if n%3==0 else 'NG'
print(result)
# NG構文
変数 = 条件1が真のときの値 if 条件式1 else 条件2が真のときの値 if 条件式2 else 条件が偽のときの値if-elif-else句
n = 55
if n%15 == 0:
result = 'FizzBuzz'
elif n%3 == 0:
result = 'Fizz'
elif n%5 == 0:
result = 'Buzz'
else:
result = n
print(result)
# Buzz三項演算子
n = 55
result = 'FizzBuzz' if n%15==0 else 'Fizz' if n%3==0 else 'Buzz' if n%5==0 else n
print(result)
# Buzzループ
構文
for 任意の変数名 in range(stop):
# stop回ループする
for 任意の変数名 in range(start, stop):
# stop-start回ループする
for 任意の変数名 in range(start, stop, step):
# (stop-start)/step回ループするrange
for i in range(5):
print(i)
# 0
# 1
# 2
# 3
# 4
for i in range(1, 6):
print(i)
# 1
# 2
# 3
# 4
# 5
for i in range(1, 11, 2):
print(i)
# 1
# 3
# 5
# 7
# 9構文
for 任意の変数名(要素) in 配列:
# 配列の先頭から末尾までループするリスト
arr = ['a', 'b', 'c', 'd', 'e']
for i in arr:
print(i)
# a
# b
# c
# d
# e構文
for 任意の変数名1(インデックス), 任意の変数名2(要素) in enumerate(配列):
# 配列の先頭から末尾までループするリスト
arr = ['a', 'b', 'c', 'd', 'e']
for index, item in enumerate(arr):
print(index, item)
# 0 a
# 1 b
# 2 c
# 3 d
# 4 e構文
for 任意の変数名1(辞書のkey), 任意の変数名2(辞書のvalue) in 辞書.items():
# 辞書の先頭から末尾までループするfruit_dict = {1001: 'apple', 1002: 'banana', 1003: 'cherry'}
for key, value in fruit_dict.items():
print(key, value)
# 1001 apple
# 1002 banana
# 1003 cherry構文
for 任意の変数名1(インデックス), 任意の変数名2(辞書のkeyとvalueのタプル) in enumerate(辞書.items()):
# 辞書の先頭から末尾までループするfruit_dict = {1001: 'apple', 1002: 'banana', 1003: 'cherry'}
for index, d in enumerate(fruit_dict.items()):
key, value = d[0], d[1]
print(index, key, value)
# 0 1001 apple
# 1 1002 banana
# 2 1003 cherry例外処理
文字列の操作
カウントする
s = 'I am Sam Braun.'
print(len(s))
# 15s = 'I am Sam Braun.'
result = s.count('am')
print(result)
# 2import re
s = 'apple-banana-blueberry-cherrt'
result = len(re.findall(pattern=r'b[a-z]+', string=s))
print(result)
# 2検索する
構文
'検索する文字列' in '検索対象の文字列'
'検索する文字列' not in '検索対象の文字列'含まれているかチェックする
print('apple' in 'apple-banana-cherry') # True
print('dorian' in 'apple-banana-cherry') # False含まれていないかチェックする
print('apple' not in 'apple-banana-cherry') # False
print('dorian' not in 'apple-banana-cherry') # True構文
import re
re.search(pattern=r'正規表現のパターン', string='検索対象の文字列')import re
s = 'apple-banana-cherry'
result = re.search(pattern=r'a...e', string=s)
if result:
print(result.group())
# apple取り出す
s = 'abcdefghij'
print(s[0]) # a
print(s[1]) # b
print(s[9]) # j
print(s[-1]) # j
print(s[-2]) # is = 'abcdefghij'
print(s[0:3]) # abc (先頭から3文字)
print(s[3:5]) # de
print(s[-3:len(s)]) # hij (末尾から3文字)| 取得したいもの | 正規表現 |
|---|---|
| ドメイン | r'[a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]\.[a-zA-Z]{2,}' |
構文
import re
re.findall(pattern=r'正規表現のパターン', string='検索対象の文字列')サンプル
import re
s = '90.2/f, 89.7/e, 91.5/a'
result = re.findall(pattern=r'\d+.\d', string=s)
print(result)
# ['90.2', '89.7', '91.5']
print([int(i) for i in result])
# [90.2, 89.7, 91.5]置換する
| 置換対象 | 正規表現 |
|---|---|
| 空白文字(半角スペース,タブ,改行,キャリッジリターン) | r'\s' |
| 半角数字 | r'[0-9]' |
| 全角半角数字 | r'\d' |
| アルファベット | r'([a-zA-Za-zA-Z])' |
| ひらがな | r'[ぁ-ゟ]' |
| カタカナ | r'[ァ-ン゙゚]' |
| 漢字 | r'[一-龥]' |
構文
import re
re.sub(pattern=r'正規表現のパターン', repl='置換文字', string='置換対象の文字列', count=0)サンプル
import re
s = '90.2/f, 89.7/e, 91.5/a'
result = re.sub(pattern=r'/[a-z]', repl='', string=s)
print(result)
# 90.2, 89.7, 91.5フォーマットを整える
num = 1/3 # 0.3333333333333333
result = '{:.2f}'.format(num)
print(result)
# 0.33last_month = 1200000
this_month = 1150000
result = '先月比は{:.2%}です。'.format(this_month/last_month)
print(result)
# 先月比は95.83%です。price = 1000000
result = 'お代は{:,}円になります。'.format(price)
print(result)
# お代は1,000,000円になります。num = 1
result = '{:0>2}'.format(num)
print(result)
# 01時系列の操作
- 日時:
datetimeモジュールのdatetimeクラス - 日付:
datetimeモジュールのdateクラス
日時
from datetime import datetime
dt = datetime.today()
print(dt)
# 2020-01-27 16:20:47.342340日付
from datetime import date
d = date.today()
print(d)
# 2020-01-27日時
from datetime import datetime
dt = datetime(2019, 5, 27, 16, 9, 57)
print(dt)
# 2019-05-27 16:09:27日付
from datetime import date
d = date(2019, 5, 27)
print(d)
# 2019-05-27
https://docs.python.org/ja/3/library/datetime.html#strftime-strptime-behavior
from datetime import datetime
dt = datetime.today() # 2020-01-27 17:32:03
print(dt.strftime('%Y-%m-%d')) # 2020-01-27
print(dt.strftime('%H:%M:%S')) # 17:32:03| 書式 | 例 | メモ |
|---|---|---|
%Y |
2020 |
4桁の西暦 |
%y |
20 |
2桁の西暦 |
%m |
02 |
2桁の月(01-12) |
%-m |
2 |
1桁の月(1-12) |
%d |
04 |
2桁の日(01-31) |
%-d |
4 |
1桁の日(1-31) |
%F |
2020-02-04 |
%Y-%m-%dと同等 |
%H |
11 |
2桁の時(00-23) |
%-H |
11 |
1桁の時(0-23) |
%M |
06 |
2桁の分(00-59) |
%-M |
6 |
1桁の分(0-59) |
%S |
07 |
2桁の秒(00-60)、60はうるう秒 |
%-S |
7 |
1桁の秒(0-60)、60はうるう秒 |
%T |
11:06:07 |
%H:%M:%Sと同等 |
%R |
11:06 |
%H:%Mと同等 |
%w |
3 |
曜日(0-6)、日曜日は0 |
from datetime import datetime, date
d = date.today() # 2020-01-27
dt = datetime.today() # 2020-01-27 17:32:03
year = dt.year # d.yearでも可
month = dt.month # d.monthでも可
day = dt.day # d.dayでも可
hour = dt.hour
minute = dt.minute
second = dt.second
print(year, month, day, hour, minute, second)
# 2020 1 27 17 32 3曜日を取得したい場合は、datetime.datetimeクラス、またはdatetime.dateクラスのweekdayメソッドを使用します。好きな方を選んで下さい。
| 戻り値 | 戻り値の型 | 説明 |
|---|---|---|
0〜6 |
int |
月〜日 |
曜日を数字で取得する
from datetime import datetime
dt = datetime.today() # 2020-01-27 17:32:03
weekday = dt.weekday()
print(weekday)
# 0曜日を漢字で取得する
from datetime import datetime
weekdays = {0: '月', 1: '火', 2: '水', 3: '木', 4: '金', 5: '土', 6: '日'}
dt = datetime.today() # 2020-01-27 17:32:03
weekday = weekdays[dt.weekday()]
print(weekday)
# 月週、日、時、分、秒を計算する
from datetime import datetime, timedelta
dt = datetime(2018, 12, 31, 16, 9, 57)
print(dt + timedelta(weeks=2)) # 2019-01-14 16:09:57
print(dt + timedelta(days=1)) # 2019-01-01 16:09:57
print(dt + timedelta(hours=8)) # 2019-01-01 00:09:57
print(dt - timedelta(minutes=10)) # 2018-12-31 15:59:57
print(dt + timedelta(seconds=20)) # 2018-12-31 16:10:17年、月を計算する
from datetime import datetime
from dateutil.relativedelta import relativedelta
dt = datetime(2020, 1, 31)
print(dt + relativedelta(years=1)) # 2021-01-31 00:00:00
print(dt + relativedelta(months=1)) # 2020-02-29 00:00:00今月の月初、月末日を取得する
from datetime import datetime, timedelta
from dateutil.relativedelta import relativedelta
dt = datetime.today() # 2020-01-01 19:46:11.567872
firsr_day = dt.replace(day=1)
last_day = (firsr_day + relativedelta(months=1)) - timedelta(days=1)
print(firsr_day) # 2020-01-01 19:46:11.567872
print(last_day) # 2020-01-31 19:46:11.567872先月の月初、月末日を取得する
from datetime import datetime, timedelta
from dateutil.relativedelta import relativedelta
dt = datetime.today() - relativedelta(months=1) # 2019-12-27 19:48:24.888953
firsr_day = dt.replace(day=1)
last_day = (firsr_day + relativedelta(months=1)) - timedelta(days=1)
print(firsr_day) # 2019-12-01 19:48:24.888953
print(last_day) # 2019-12-31 19:48:24.888953任意の月初、月末日を取得する
from datetime import datetime, timedelta
from dateutil.relativedelta import relativedelta
year = 2020
month = 2
dt = datetime(year, month, 1) # 2020-02-01 00:00:00
firsr_day = dt.replace(day=1)
last_day = (firsr_day + relativedelta(months=1)) - timedelta(days=1)
print(firsr_day) # 2020-02-01 00:00:00
print(last_day) # 2020-02-29 00:00:00from datetime import date
start_day = date.today() # 2020-01-27
end_day = date(start_day.year, 12, 25)
days = (end_day - start_day).days
print('次のクリスマスまで、あと{}日!'.format(days))
# 次のクリスマスまで、あと333日!from datetime import date, timedelta
start_day = date(2019, 2, 27)
end_day = date(2019, 3, 2)
days = (end_day - start_day).days + 1
dates = [start_day + timedelta(days=i) for i in range(days)]
print(dates)
# [datetime.date(2019, 2, 27), datetime.date(2019, 2, 28), datetime.date(2019, 3, 1), datetime.date(2019, 3, 2)]from datetime import datetime
def checkDate(year, month, day):
try:
new_date_str = '{0:0>4}-{1:0>2}-{2:0>2}'.format(year, month, day)
new_date = datetime.strptime(new_date_str, '%Y-%m-%d')
return True
except Exception as e:
return False
print(checkDate(2019, 5, 31)) # True
print(checkDate(2019, 5, 32)) # False配列の操作
作成
リスト内包表記
配列の要素をまとめて処理するときに使います。
構文
[処理 for 任意の変数名 in 1次元配列]forループ
arr = ['0001', '0002', '0003', '0004', '0005']
for index, i in enumerate(arr):
arr[index] = int(i)
print(arr)
# [1, 2, 3, 4, 5]リスト内包表記
arr = ['0001', '0002', '0003', '0004', '0005']
print([int(i) for i in arr])
# [1, 2, 3, 4, 5]構文
[処理 for 任意の変数名 in 1次元配列 if 条件式]forループ
arr = []
for i in range(1, 11):
if i%2 == 0:
arr.append(i)
print(arr)
# [2, 4, 6, 8, 10]リスト内包表記
arr = [i for i in range(1, 11) if i%2 == 0]
print(arr)
# [2, 4, 6, 8, 10]構文
[真の処理 if 条件式 else 偽の処理 for 任意の変数名 in 1次元配列]forループ
arr = []
for i in range(1, 11):
if i%2==0:
arr.append(i**2)
else:
arr.append(i)
print(arr)
# [1, 4, 3, 16, 5, 36, 7, 64, 9, 100]リスト内包表記
arr = [i**2 if i%2==0 else i for i in range(1, 11)]
print(arr)
# [1, 4, 3, 16, 5, 36, 7, 64, 9, 100]構文
[条件式1が真の処理 if 条件式1 else 条件式2が真の処理 if 条件式2 else 偽の処理 for 任意の変数名 in 1次元配列]forループ
arr = []
for i in range(1, 16):
if i%15==0:
arr.append('fizzbuzz')
elif i%3==0:
arr.append('fizz')
elif i%5==0:
arr.append('buzz')
else:
arr.append(i)
print(arr)
# [1, 2, 'fizz', 4, 'buzz', 'fizz', 7, 8, 'fizz', 'buzz', 11, 'fizz', 13, 14, 'fizzbuzz']リスト内包表記
arr = ['fizzbuzz' if i%15==0 else 'fizz' if i%3==0 else 'buzz' if i%5==0 else i for i in range(1, 16)]
print(arr)
# [1, 2, 'fizz', 4, 'buzz', 'fizz', 7, 8, 'fizz', 'buzz', 11, 'fizz', 13, 14, 'fizzbuzz']配列を比較する
配列の要素を比較する場合、一度組み込み型のsetメソッドでset型(集合)に変換して、集合の演算を行います。
そして、組み込み型のlistメソッドで集合を配列に戻します。

構文
集合a | 集合b2つの配列の和集合
a = set([1, 2, 3, 4, 5, 6]) # {1, 2, 3, 4, 5, 6}
b = set([4, 5, 6, 7, 8, 9]) # {4, 5, 6, 7, 8, 9}
result = list(a|b)
print(result)
# [1, 2, 3, 4, 5, 6, 7, 8, 9]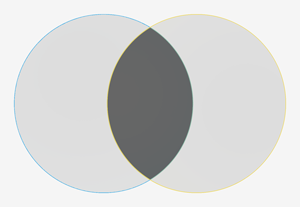
構文
集合a & 集合b2つの配列の積集合
a = set([1, 2, 3, 4, 5, 6]) # {1, 2, 3, 4, 5, 6}
b = set([4, 5, 6, 7, 8, 9]) # {4, 5, 6, 7, 8, 9}
result = list(a&b)
print(result)
# [4, 5, 6]
構文
集合a ^ 集合b2つの配列の対象差集合
a = set([1, 2, 3, 4, 5, 6]) # {1, 2, 3, 4, 5, 6}
b = set([4, 5, 6, 7, 8, 9]) # {4, 5, 6, 7, 8, 9}
result = list(a^b)
print(result)
# [1, 2, 3, 7, 8, 9]
構文
集合a - 集合b
集合b - 集合a2つの配列の差集合(a - b)
a = set([1, 2, 3, 4, 5, 6]) # {1, 2, 3, 4, 5, 6}
b = set([4, 5, 6, 7, 8, 9]) # {4, 5, 6, 7, 8, 9}
result = list(a-b)
print(result)
# [1, 2, 3]2つの配列の差集合(b - a)
a = set([1, 2, 3, 4, 5, 6]) # {1, 2, 3, 4, 5, 6}
b = set([4, 5, 6, 7, 8, 9]) # {4, 5, 6, 7, 8, 9}
result = list(b-a)
print(result)
# [7, 8, 9]要素を検索する
要素の並べ替え
要素の削除
処理を速くしたければ、リスト内包表記を使用します。
forループ
arr = ['', 'a', 'b', '', 'c']
result = []
for s in arr:
if s!='':
result.append(s)
print(result)
# ['a', 'b', 'c']リスト内包表記
arr = ['', 'a', 'b', '', 'c']
result = [s for s in arr if s!='']
print(result)
# ['a', 'b', 'c']filterメソッドとラムダ式
arr = ['', 'a', 'b', '', 'c']
result = list(filter(lambda s:s != '', arr))
print(result)
# ['a', 'b', 'c']元のリストの順序を保持しない
arr = ['b', 'a', 'c', 'a', 'b', 'd']
result = list(set(arr))
print(result)
# ['b', 'c', 'a', 'd']元のリストの順序を保持する
arr = ['b', 'a', 'c', 'a', 'b', 'd']
result = sorted(set(arr), key=arr.index)
print(result)
# ['b', 'a', 'c', 'd']辞書の操作
辞書型配列
pg_lang_dict = {
'Python': {
'拡張子': '.py',
'略語': 'Py',
'出力': 'print(値)',
'フレームワーク': {
'Django': {
'type': 'フルスタック',
'dev_scale': '中〜大規模',
'case_study': ['Instagram', 'Youtube', 'Spotify'],
'doc': 'https://docs.djangoproject.com/ja/3.0/',
},
'Flask': {
'type': 'マイクロフレームワーク',
'dev_scale': '小〜中規模',
'case_study': ['Netflix', 'Pinterest'],
'doc': 'https://flask.palletsprojects.com/en/1.1.x/'
}
}
},
'JavaScript': {
'拡張子': '.js',
'略語': 'JS',
'出力': 'console.log(値);',
'フレームワーク': ['Angular', 'React', 'Vue.js']
},
'Ruby': {
'拡張子': '.rb',
'略語': 'Rb',
'出力': 'puts 値',
'フレームワーク': ['Ruby on Rails', 'Sinatra']
}
}作成する
構文
dict(zip([キーになる配列], [値になる配列]))配列
keys = [1001, 1002, 1003]
values = ['apple', 'banana', 'cherry']
fruit_dict = dict(zip(keys, values))
print(fruit_dict)
# {1001: 'apple', 1002: 'banana', 1003: 'cherry'}range関数
keys = range(3)
values = ['apple', 'banana', 'cherry']
fruit_dict = dict(zip(keys, values))
print(fruit_dict)
# {0: 'apple', 1: 'banana', 2: 'cherry'}