
この記事では、Heroku Postgresの導入から初期設定、PandasとSQLAlchemyモジュールでデータベースを読み書きする方法を紹介しています。
Heroku Postgresは無料プラン(正しくは、Hobby Devプラン)で1万レコードまで使用することができ、Webアプリケーションの簡単な開発テスト、スクレイピングのデータの保管場所にぴったりです。
さっそく導入方法を見てみましょう。
目次

データサイエンティスト / ブロガー
たぬ
tanu
福岡在住のデータサイエンティスト。Pythonでルーチンワークを瞬殺する仕組みを作ることやデータを視覚化することが得意です。
Heroku Postgresを導入する
$ heroku loginHeroku Postgresを使用する場合、無料有料枠問わずクレジットカードの登録が必須です。先にアカウントページでクレジットカードを登録させましょう。
$ heroku addons:create heroku-postgresql:hobby-dev -a {{ アプリ名 }}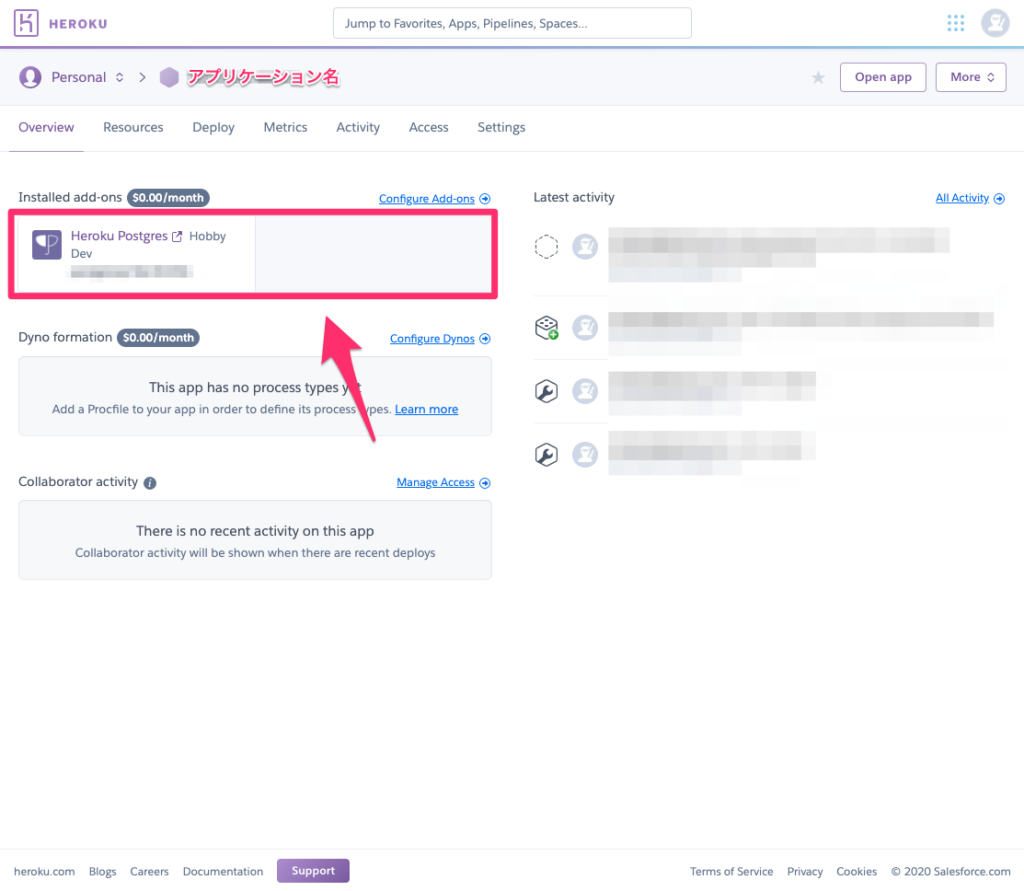
アプリ名が分からない場合は、heroku appsコマンドで、Herokuアカウントに登録されているアプリケーション一覧が表示されます。
$ heroku apps=== アカウント名 Apps
アプリケーション名1
アプリケーション名2
アプリケーション名3アプリが無い場合、heroku createコマンドを使用して新規作成します。
作成方法にはアプリケーション名を指定する方法としない方法の2パターンがあります。指定しない場合、適当な名前が設定されます。
$ heroku create
$ heroku apps:create {{ 任意のアプリ名 }}$ heroku pg:info -a {{ アプリ名 }}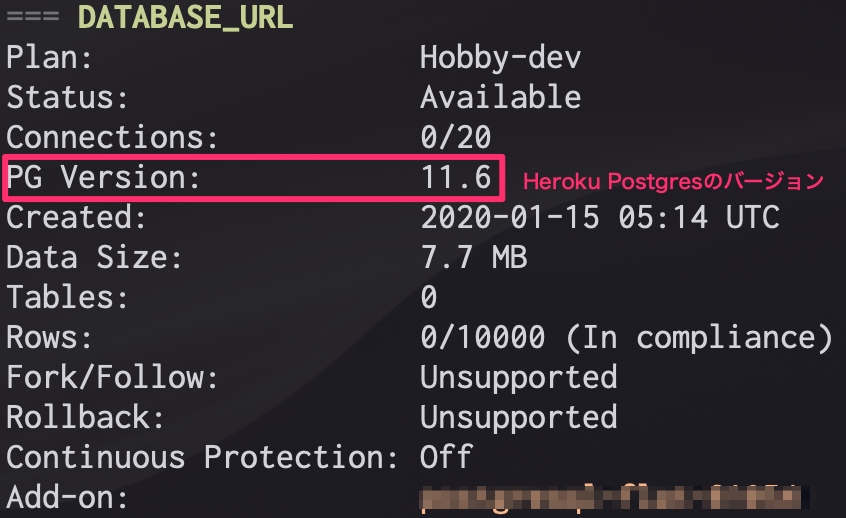
Heroku Postgresの初期設定
この章では、PandasからHeroku Postgresを操作するためのセットアップを行います。
ターミナルから接続する
$ heroku pg:psql -a {{ アプリ名 }}psqlコマンドが使えない人は、Homebrewを使ってPostgreSQLをローカルPCにインストールします。
$ brew install postgresql>>>$ psql -V
psql (PostgreSQL) 11.2タイムゾーンを変更する
Herokuのサーバー上のタイムゾーンは、デフォルトでUTC時間になっているので、日本時間(Asia/Tokyo)に変更します。
select current_timestamp; current_timestamp
-------------------------------
2020-01-15 06:49:43.847471+00
(1 row)Asia/Tokyoに変更するalter database {{ データベース名 }} set timezone = 'Asia/Tokyo';以下のコマンドで、アプリケーションに紐付いているデータベースのURLを得ることができます。
$ heroku config --app {{ アプリ名 }}DATABASE_URL: postgres://{{ User }}:{{ Password }}@{{ Host }}:{{ Port }}/{{ Database }}ちゃんと変更されたか、もう一度確認します。
\qコマンドで一度DBからログアウトして、heroku pg:psqlコマンドで接続し直します。
select current_timestamp; current_timestamp
-------------------------------
2020-01-15 15:52:56.008592+09
(1 row)ちゃんと9時間後に設定されましたね!
テーブルを作成する
- 1列目:id(
integer) PRIMARY KEY - 2列目:name(
varchar(100))
create table {{ 任意のテーブル名 }}(
id integer not null,
name varchar(100) not null,
primary key (id)
);メタコマンド\dでテーブル情報を確認してみましょう
\d {{ テーブル名 }} Table "public.{{ テーブル名 }}"
Column | Type | Collation | Nullable | Default
--------+------------------------+-----------+----------+---------
id | integer | | not null |
name | character varying(100) | | not null |
Indexes:
"{{ テーブル名 }}_pkey" PRIMARY KEY, btree (id)insert into {{ テーブル名 }} (id, name) values (1, 'tanu');
insert into {{ テーブル名 }} (id, name) values (2, 'hack');select * from sample; id | name
----+------
1 | tanu
2 | hack
(2 rows)おまけ:DB関連のコマンドまとめ
・カラムの型変換 : ALTER TABLE テーブル名 ALTER COLUMN カラム名 TYPE データ型
・データベース情報の確認 : \d
・テーブル情報の確認 : \d {{ テーブル名 }}
PandasでPostgreSQLを操作する
個人的に、PythonからPostgreSQLのレコードを読み込んだり追加したりする方法で、もっとも簡単かつラクな方法を紹介します。
それはpandas.DataFrameのsql系のメソッドを使う方法です。
read_sql(): データベースのテーブルをpandas.DataFrameとして読み込むto_sql():pandas.DataFrameをデータベースのテーブルに追加する
それぞれ順に紹介します。
DataFrameとしてテーブルを読み込む
pandas.DataFrameのread_sqlメソッドを使用すると、PostgreSQLのテーブルをDataFrameとして変数に格納することが出来ます。
df = pd.read_sql(sql, con)必須パラメータは、以下の2つです。
sqlパラメータ : SQLクエリまたはテーブル名conパラメータ : SQLAlchemyのサーバー接続エンジンまたはデータベースURL
もっと詳しくパラメータのことを知りたい方は、Pandasの公式ページからどうぞ
データベースとDataFrameを繋げるためにO/RマッパーであるSQLAlchemyモジュールをインストールします。
pip install sqlalchemyそれでは、pandas.DataFrameのread_sqlメソッドとsqlalchemyクラスのcreate_engineメソッドを使用して、PostgreSQLからテーブルをDataFrameに格納するサンプルプログラムを見てみましょう。
import pandas as pd
from sqlalchemy import create_engine
# PostgreSQLのサーバー接続エンジンを作成する
engine = create_engine('{{ データベースのURL }}')
# 変数dfにPostgreSQLの指定したテーブルの全レコードをpandas.DataFrameとして格納する
df = pd.read_sql(sql='SELECT * FROM {{ テーブル名 }};', con=engine)
print(df) id name
0 1 tanu
1 2 hack以下のコマンドでHerokuのアプリケーションに紐付けられているデータベースのURLを得ることが出来ます。
$ heroku config --app {{ アプリ名 }}DATABASE_URL: postgres://{{ User }}:{{ Password }}@{{ Host }}:{{ Port }}/{{ Database }}テーブルにDataFrameを追加する
pandas.DataFrameのto_sqlメソッドを使用すると、PostgreSQLに存在するテーブルにDataFrameを追加することが出来ます
pandas.DataFrame.to_sql(name, con, if_exists='append', index)設定するパラメータは、以下の4つです。
nameパラメータ : 追加先のテーブル名conパラメータ : SQLAlchemyのサーバー接続エンジンif_existsパラメータ : 値をappendにするとテーブルに追加できますindexパラメータ : DataFrameのインデックスをテーブルに追加するかどうか
もっと詳しくパラメータのことを知りたい方は、Pandasの公式ページからどうぞ
pandas.DataFrameのto_sqlメソッドについて補足すると、デフォルトのデータベースはSQLiteなので、必ずconパラメータにはデータベースのURLではなく、SQLAlchemyのサーバー接続エンジンを指定しなければいけません。
import pandas as pd
from sqlalchemy import create_engine
# PostgreSQLのサーバー接続エンジンを作成する
engine = create_engine('{{ データベースのURL }}')
# 適当なDataFrameを作成する(ただし、カラム名は必ずデータベースのものと同じにする)
df = pd.DataFrame(data=[[3, 'たぬ'], [4, 'ハック']], columns=['id', 'name'])
# id name
# 0 3 たぬ
# 1 4 ハック
# PostgreSQLの指定したテーブルにpandas.DataFrameを追加する
df.to_sql('{{ テーブル名 }}', con=engine, if_exists='append', index=False)ターミナルに戻って、ちゃんとデータベースに追加されているか確認しましょう。
select * from sample; id | name
----+-------
1 | tanu
2 | hack
3 | たぬ
4 | ハック
(4 rows)きちんと追加されていましたね。
nameパラメータのテーブル名を間違えてしまうと、PostgreSQLに新しくテーブルが作成されてしまうので注意しましょう。
