環境設定
開発環境
| OS |
MacOS Mojave 10.14.5 |
| Jupyter Notebook |
6.0.3 |
| conda |
4.8.3 |
| Python |
3.6.10 |
| pandas |
1.0.3 |
| NumPy |
1.18.1 |
モジュールのインポート
基本モジュールのインポート
import pandas as pd
import numpy as np
便利なコマンド集
| 逆引き |
コマンド |
| 常に全カラム表示 |
pd.set_option('display.max_columns', None) |
| pandasのバージョンを表示 |
pd.__version__ |
| NumPyのバージョンを表示 |
np.__version__ |
| 依存パッケージなどの詳細情報を表示 |
pd.show_versions(as_json=False) |
Jupyter Notebook
| 逆引き |
コマンド |
| Jupyter Notebookを起動 |
$ jupyter notebook |
| Jupyterの諸々のバージョンを確認 |
$ jupyter --version |
| Anacondaをアップデート |
$ sudo conda update anaconda |
| JupyterのPythonをアップデート(3.6.8→3.6.10) |
$ conda update python |
| Jupyterのモジュール全てをアップデート |
$ conda update --all |
| Jupyterのモジュールを個別にアップデート(pandas) |
$ conda update pandas |
ショートカットキー
コマンドモード(Mac OS)
| 逆引き |
コマンド |
| 編集モード |
Enter |
| セルを実行 |
Control+Enter |
| セルを実行し、下のセルに移動 |
Shift+Enter |
| 上のセルを選択する |
K |
↑ |
| 下のセルを選択する |
J |
↓ |
| セルをコピー |
C |
| セルを切り取り |
X |
| 下に貼り付け |
V |
| 保存 |
S |
Command+S |
| 上にセルを追加する |
A |
| 下にセルを追加する |
B |
| セルを削除する |
D+D |
| セルの削除をやり直す |
Z |
| 検索と置換 |
F |
| 上にスクロール |
Shift+Space |
| 下にスクロール |
Space |
| コードセルにする |
Y |
| マークダウンセルにする |
M |
| ショートカットキーの一覧を表示 |
H |
編集モード(Mac OS)
| 逆引き |
コマンド |
| コマンドモード(編集モードを解除) |
Esc |
| インデント |
Tab |
Command+] |
| アンインデント(逆インデント) |
Shiht+Tab |
Command+[ |
| コメントアウト |
Command+/ |
| コード補完 |
Tab |
| ツールチップを表示 |
Shift+Tab |
| セルを保存 |
Command+S |
| セルを実行 |
Control+Enter |
| セルを実行し、下のセルに移動 |
Shift+Enter |
マジックコマンド
| 逆引き |
コマンド |
| Jupyter Notebook内にmatplotlibを描画 |
%matplotlib inline |
| .ipyrbファイルのディレクトリを確認 |
%pwd |
| セルの実行時間を1回計測 |
%%time |
| セルの実行時間を複数回計測 |
%%timeit |
その他のJupyter Notebookの便利設定はこちらのリンクに丁寧にまとめてありました。
参考
Jupyter 知っておくと少し便利なTIPS集Qiita
データ構造
pandas.Series
シリーズは1次元配列のようなオブジェクトです。シリーズには連続したデータ値とそれに関連付けられたインデックスというデータラベルの2つの配列が含まれています。
シリーズを作成
s = pd.Series(data=[295, 201, 7])
print(s.to_markdown())
# | | 0 |
# |---:|----:|
# | 0 | 295 |
# | 1 | 201 |
# | 2 | 7 |
注意
pandas.Series.to_markdownメソッドやpandas.DataFrame.to_markdownメソッドは、pandasのバージョンが1系だと使うことができます。
コンソールに出力されているシリーズの文字列表現では、インデックスが左側、データ値が右側に表示されます。この例では、データに対するインデックスを指定していなかったので、0からN-1までのデフォルトのインデックスが割り当てられています。
シリーズのvalues属性とindex属性を使うと、データ配列とインデックスをそれぞれ取得することができます。
print(s.values)
# array([295, 201, 7])
print(s.index)
# RangeIndex(start=0, stop=3, step=1)
# range(3)と等しい
各データを特定するためにインデックス付きのシリーズの方が好ましい場合もあります。
インデックス付きのシリーズを作成
s = pd.Series(data=[295, 201, 7], index=['apple', 'banana', 'cherry'])
print(s.to_markdown())
# | | 0 |
# |:-------|----:|
# | apple | 295 |
# | banana | 201 |
# | cherry | 7 |
print(s.index)
# Index(['apple', 'banana', 'cherry'], dtype='object')
インデックス付きのシリーズは辞書からも作成することができ、シリーズをインデックスとデータ値がマッピングされた固定長の順序付きとして扱うことができます。
インデックス付きのシリーズを辞書から作成
s = pd.Series(data={'apple': 295, 'banana': 201, 'cherry': 7}))
print(s.to_markdown())
# | | 0 |
# |:-------|----:|
# | apple | 295 |
# | banana | 201 |
# | cherry | 7 |
print('apple' in s)
# True
print('dorian' in s)
# False
for index, (key, value) in enumerate(s.items()):
print(index, key, value)
# 0 apple 295
# 1 banana 201
# 2 cherry 7
シリーズのデータ配列の各要素には、リストまたは辞書のようにアクセスすることができます。
シリーズの各要素にアクセス
print(s['banana'])
# 201
print(s[-1])
# 7
print(s[0:2].to_markdown())
# | | 0 |
# |:-------|----:|
# | apple | 295 |
# | banana | 201 |
print(s[['apple', 'cherry']].to_markdown())
# | | 0 |
# |:-------|----:|
# | apple | 295 |
# | cherry | 7 |
print(s[[False, True, True]].to_markdown())
# | | 0 |
# |:-------|----:|
# | banana | 201 |
# | cherry | 7 |
他にもシリーズに対して、条件指定によるフィルタリングやスカラー値の演算、数学的な関数を行うことができます。
シリーズの操作
print(s[s>100].to_markdown())
# | | 0 |
# |:-------|----:|
# | apple | 295 |
# | banana | 201 |
print((s*3).to_markdown())
# | | 0 |
# |:-------|----:|
# | apple | 885 |
# | banana | 603 |
# | cherry | 21 |
print(np.sqrt(s).to_markdown())
# | | 0 |
# |:-------|---------:|
# | apple | 17.1756 |
# | banana | 14.1774 |
# | cherry | 2.64575 |
また、シリーズのデータ配列とインデックスはそれぞれname属性を持ちます。
name属性に値を代入
s.name = 'weight'
s.index.name = 'fruits'
print(s.to_markdown())
# | fruits | weight |
# |:---------|---------:|
# | apple | 295 |
# | banana | 201 |
# | cherry | 7 |
後述しますが、このname属性は、データフレームの列名に関わり合う部分になっています。
pandas.DataFrame
データフレームは、テーブル形式(縦持ち)のデータ構造を持ち、列ごとに様々なデータ型(数値型、文字列型、ブール型など)を持っています。
そして、行と列の両方にインデックスを持っており、シリーズを値として持つ辞書として見ることができます。(同じインデックスを持つ複数のシリーズを結合したものをデータフレームと言います。)
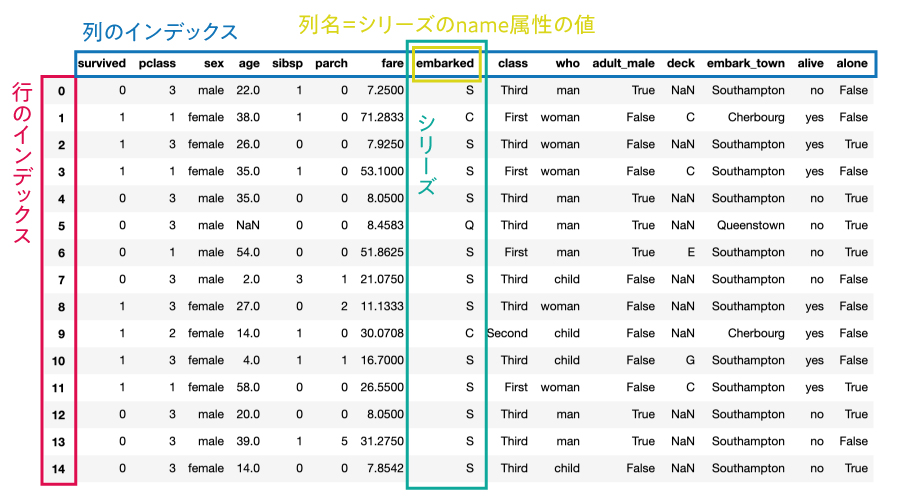
データフレームを作成する最も簡単な方法は、同じ長さの1次元配列を値に持つ辞書を使う方法です。
同じ長さの1次元配列を値に持つ辞書からデータフレームを作成
data = {
'weight(g)': [295, 201, 7],
'kcal/100g': [61, 86, 60],
'brix(%)': [15, 21, 16]
}
df = pd.DataFrame(data=data)
print(df.to_markdown())
# | | weight(g) | kcal/100g | brix(%) |
# |---:|------------:|------------:|----------:|
# | 0 | 295 | 61 | 15 |
# | 1 | 201 | 86 | 21 |
# | 2 | 7 | 60 | 16 |
作成されたデータフレームは行のインデックスを指定していないので、シリーズと同じように0〜N-1までのデフォルトのインデックスが割り当てられています。
また、データフレームのvalues属性とindex属性、columns属性を使うと、データ配列と行、列のインデックスをそれぞれ取得することができます。
データ配列と行、列のインデックスをそれぞれ取得
print(df.values)
# array([[295, 61, 15],
# [201, 86, 21],
# [ 7, 60, 16]])
print(df.index)
# RangeIndex(start=0, stop=3, step=1)
print(df.columns)
# Index(['weight(g)', 'kcal/100g', 'brix(%)'], dtype='object')
pandas.DataFrameメソッドのindexパラメータに、データ配列と同じ長さのデータラベルを設定すると、データフレームのインデックスを設定することができます。
インデックスを設定してデータフレームを作成する
df = pd.DataFrame(data=data, index=['apple', 'banana', 'cherry'])
print(df.to_markdown())
# | | weight(g) | kcal/100g | brix(%) |
# |:-------|------------:|------------:|----------:|
# | apple | 295 | 61 | 15 |
# | banana | 201 | 86 | 21 |
# | cherry | 7 | 60 | 16 |
他にも、2次元配列やシリーズからデータフレームを作成する方法もあります。
2次元配列からデータフレームを作成する
data = [
[295, 61, 15],
[201, 86, 21],
[7, 60, 16]
]
df = pd.DataFrame(data=data, index=['apple', 'banana', 'cherry'], columns=['weight(g)', 'kcal/100g', 'brix(%)'])
print(df.to_markdown())
# | | weight(g) | kcal/100g | brix(%) |
# |:-------|------------:|------------:|----------:|
# | apple | 295 | 61 | 15 |
# | banana | 201 | 86 | 21 |
# | cherry | 7 | 60 | 16 |
name属性の値が無いシリーズからデータフレームを作成する
s1 = pd.Series([295, 201, 7], index=['apple', 'banana', 'cherry'])
s2 = pd.Series([61, 86, 60], index=['apple', 'banana', 'cherry'])
s3 = pd.Series([15, 21, 16], index=['apple', 'banana', 'cherry'])
df = pd.DataFrame(data={'weight(g)': s1, 'kcal/100g': s2, 'brix(%)': s3})
print(df.to_markdown())
# | | weight(g) | kcal/100g | brix(%) |
# |:-------|------------:|------------:|----------:|
# | apple | 295 | 61 | 15 |
# | banana | 201 | 86 | 21 |
# | cherry | 7 | 60 | 16 |
name属性の値があるシリーズからデータフレームを作成する
s1 = pd.Series([295, 201, 7], index=['apple', 'banana', 'cherry'], name='weight(g)')
s2 = pd.Series([61, 86, 60], index=['apple', 'banana', 'cherry'], name='kcal/100g')
s3 = pd.Series([15, 21, 16], index=['apple', 'banana', 'cherry'], name='brix(%)')
df = pd.concat([s1, s2, s3], axis=1)
print(df.to_markdown())
# | | weight(g) | kcal/100g | brix(%) |
# |:-------|------------:|------------:|----------:|
# | apple | 295 | 61 | 15 |
# | banana | 201 | 86 | 21 |
# | cherry | 7 | 60 | 16 |
データフレームの行や列、値は以下のようにして取り出すことができます。
データフレームから列を取り出す
print(df['weight(g)'].to_markdown())
# | | weight(g) |
# |:-------|------------:|
# | apple | 295 |
# | banana | 201 |
# | cherry | 7 |
データフレームから行を取り出す
print(df.loc['banana'].to_markdown())
# | | banana |
# |:----------|---------:|
# | weight(g) | 201 |
# | kcal/100g | 86 |
# | brix(%) | 21 |
データフレームから値を取り出す
print(df.loc['banana', 'weight(g)'])
# 201
他にもデータを抽出する方法はたくさんありますが、ここでは割愛します。詳しくは、5.データ抽出を参照してください。
基本操作まとめ
シリーズ
| 逆引き |
コマンド |
戻り値 |
| 1次元配列から作成 |
pd.Series(data=[データ配列], [index=[インデックス]]) |
pd.Series |
| 辞書から作成 |
pd.Series(data={'インデックス': データ値,…}) |
pd.Series |
| インデックスを取得 |
s.index |
pd.Index |
| データ配列を取得 |
s.values |
np.ndarray |
| インデックスのname属性を取得 |
s.index.name |
str |
| データ配列のname属性を取得 |
s.name |
str |
| 一意な値のリストを取得 |
s.unique() |
np.ndarray |
| 一意な値の出現頻度をカウント |
s.value_counts() |
pd.Series |
| 辞書に変換 |
s.to_dict() |
dict |
| リストに変換 |
s.to_list() |
list |
| コピー |
s.copy() |
pd.Series |
| マークダウンテーブルに変換 |
s.to_markdown() |
str |
| 関数を全要素に適用 |
s.apply(lambda x:func(x)) |
pd.Series |
データフレーム
| 逆引き |
コマンド |
戻り値 |
| 1次元配列を値に持つ辞書から作成 |
pd.DataFrame(data={'列名': arr_1d, …}) |
pd.DataFrame |
| 2次元配列から作成 |
pd.DataFrame(data=arr_2d, columns=[列名のリスト]) |
pd.DataFrame |
| name属性がないシリーズから作成 |
pd.DataFrame(data={'列名': s1, '列名': s2, …}) |
pd.DataFrame |
| name属性があるシリーズから作成 |
pd.concat([s1, s2, …], axis=1) |
pd.DataFrame |
| データ配列を取得 |
df.values |
np.ndarray |
| 行のインデックスを取得 |
df.index |
pd.Index |
| 列のインデックスを取得 |
df.columns |
pd.Index |
| コピー |
df.copy() |
pd.DataFrame |
| 転置 |
df.T |
pd.DataFrame |
| マークダウンテーブルに変換 |
df.to_markdown() |
str |
| 関数を全要素に適用 |
df.applymap(lambda x:func(x)) |
pd.DataFrame |
データI/O
CSVファイル
このセクションで使用する追加モジュール
| コマンド |
用途 |
追加のインストール |
from glob import glob |
CSVをワイルドカードを使って読み込む |
なし |
import csv |
CSVをダブルクオートして書き出す |
なし |
CSVファイルを読み込む
pandas.read_csvメソッドを使用して、CSVファイルをpandas.DataFrameとして読み込むことができます。
pandas.read_csv
CSVファイルをデータフレームとして読み込む
df = pd.read_csv('CSVファイルのパス')
| 逆引き |
コマンド |
| 日本語が含まれるファイルを読み込む |
pd.read_csv('sample.csv', encoding='cp932') |
| Pythonオブジェクト型として読み込む |
pd.read_csv('sample.csv', dtype=object) |
| ヘッダーを設定して読み込む |
pd.read_csv('sample.csv', names=[列名のリスト]) |
| インデックスを設定して読み込む |
pd.read_csv('sample.csv', index_col='列名') |
| 先頭から任意の行スキップして読み込む |
pd.read_csv('sample.csv', skiprows=行数) |
| 末尾から任意の行スキップして読み込む |
pd.read_csv('sample.csv', skipfooter=行数, engine='python') |
| 先頭から任意の行だけ読み込む |
pd.read_csv('sample.csv', nrows=行数) |
| 指定した列名だけ読み込む |
pd.read_csv('sample.csv', usecols=[列名のリスト]) |
| ワイルドカードで読み込む |
pd.read_csv(glob('*.csv')) |
| 複数のCSVをまとめて1つに読み込む |
csv_files_path = sorted(glob('*.csv'))
marge_csv = [pd.read_csv(f) for f in csv_files_path]
pd.concat(marge_csv, ignore_index=True) |
複数のCSVファイルを1つのDataFrameにマージしたいときは
sample1.csv
"col1","col2"
"1001","あいうえお"
"1002","かきくけこ"
"1003","さしすせそ"
sample2.csv
"col1","col2"
"1004","たちつてと"
"1005","なにぬねの"
"1006","はひふへほ"
sample3.csv
"col1","col2"
"1007","まみむめも"
"1008","やゆよ"
"1009","らりるれろ"
forループと標準モジュールのglopを使用し、指定したディレクトリからCSVファイルをまとめて順番にインポートとして、pandas.concatメソッドで、1つのデータフレームにマージします。
csv_files_path = sorted(glob('sample*.csv'))
marge_csv = []
for f in csv_files_path:
marge_csv.append(pd.read_csv(f, encoding='cp932'))
# 1つのデータフレームに結合する
# ignore_index=Trueでインデックスをリセット
df = pd.concat(marge_csv, ignore_index=True)
print(df)
# col1 col2
# 0 1001 あいうえお
# 1 1002 かきくけこ
# 2 1003 さしすせそ
# 3 1004 たちつてと
# 4 1005 なにぬねの
# 5 1006 はひふへほ
# 6 1007 まみむめも
# 7 1008 やゆよ
# 8 1009 らりるれろ
CSVファイルを書き出す
pandas.DataFrame.to_csvメソッドを使用して、pandas.DataFrameをCSVファイルとして書き出すことができます。
pandas.DataFrame.to_csv
データフレームをCSVファイルとして書き出す
df.to_csv('保存先のCSVファイルのパス')
| 逆引き |
コマンド |
| インデックスを無視して書き出す |
df.to_csv('sample.csv', index=False) |
| 日本語が含まれるファイルを書き出す |
df.to_csv('sample.csv', encoding='cp932') |
| ダブルクオートして書き出す |
df.to_csv('sample.csv', quoting=csv.QUOTE_ALL) |
| ファイルを任意の行数ごと分割して書き出す |
n=任意の行数
for index, divided_df in df.groupby(by=df.index//n):
divided_df.to_csv('sample_{}.csv'.format(index)) |
 【Python】PandasでCSVファイルを読み込み/書き出しする実践テクニック集
【Python】PandasでCSVファイルを読み込み/書き出しする実践テクニック集
Excelファイル
このセクションで使用する追加モジュール
| コマンド |
用途 |
追加のインストール |
from glob import glob |
Excelをワイルドカードを使って読み込む |
なし |
Googleスプレッドシート
このセクションで使用する追加モジュール
| コマンド |
用途 |
追加のインストール |
import gspread |
スプレッドシートを操作する |
$ pip install gspread |
from oauth2client.service_account import ServiceAccountCredentials |
GoogleAPIの認証 |
$ pip install oauth2client |
PostgreSQL
このセクションで使用する追加モジュール
| コマンド |
用途 |
追加のインストール |
from sqlalchemy import create_engine |
PostgreSQLに接続する |
$ pip install sqlalchemy |
PostgreSQLのテーブルを読み込む
pandas.read_sqlメソッドを使用して、PostgreSQLのテーブルをpandas.DataFrameとして読み込むことができます。
pandas.read_sql
PostgreSQLのテーブルをデータフレームとして読み込む
df = pd.read_sql(sql='SELECT * FROM テーブル名;', con=create_engine('データベースのURL'))
PostgreSQLのテーブルに追加する
pandas.DataFrame.read_sqlメソッドを使用すると、PostgreSQLに存在するテーブルにpandas.DataFrameを追加することができます。
pandas.DataFrame.to_sql
データフレームをPostgreSQLのテーブルに追加する
df.to_sql(name='テーブル名', con=create_engine('データベースのURL'), if_exists='append', index=False)
 PandasとSQLAlchemyでPostgreSQL(Heroku Postgres)を読み書きする方法
PandasとSQLAlchemyでPostgreSQL(Heroku Postgres)を読み書きする方法
お手軽サンプルデータセットを読み込む
このセクションで使用する追加モジュール
| コマンド |
用途 |
追加のインストール |
import seaborn as sns |
サンプルデータセットを読み込む |
$ pip install seaborn |
matplotlibラッパーのseabornモジュール(Pythonの可視化ライブラリ)をインポートし、seaborn.load_datasetメソッドで、サンプルデータセットを簡単に読み込むことができます。
読み込んだデータセットはpandas.DataFrameとして格納されるので、データ処理の余計な手間が省けて便利です。
seaborn.load_dataset
seabornモジュールのデータセットを読み込む
df = sns.load_dataset('データセット名')
| 逆引き |
コマンド |
| アヤメの品種分類データ |
sns.load_dataset('iris') |
| タイタニック号の乗客データ |
sns.load_dataset('titanic') |
| ダイヤモンドの価格を決めるcarat、cut、color、clarityなどに関するデータ |
sns.load_dataset('diamonds') |
| 2014年までに発見された1,000以上の惑星データ |
sns.load_dataset('planets') |
| レストランスタッフが受け取ったチップの金額と関連データ |
sns.load_dataset('tips') |
その他のデータセットは、公式のGitHubを確認してください。
データ前処理の前処理
データの全体像を把握
データのチラ見
| 逆引き |
コマンド |
| 先頭5行を抽出 |
df.head() |
| 末尾5行を抽出 |
df.tail() |
行数、列数の確認
| 逆引き |
コマンド |
| 行数 |
len(df) |
| 列数 |
len(df.columns) |
| 次元数(行数と列数) |
df.shape |
データ型の処理
データ型の確認
| 逆引き |
コマンド |
| データ型の確認 |
df.dtypes |
| 有効データ数、データ型、メモリ使用量の確認 |
df.info() |
キャスト(型変換)
| 逆引き |
コマンド |
| 整数型に型変換 |
df['列名'].astype('int') |
| 浮動小数点型に型変換 |
df['列名'].astype('float') |
| 文字型に型変換 |
df['列名'].astype('str') |
| ブール型に型変換 |
df['列名'].astype('bool') |
| Pythonオブジェクト型に型変換 |
df['列名'].astype('object') |
| 文字型から日時型に型変換 |
pd.to_datetime(df['列名']) |
| シリアル値から日時型に型変換 |
pd.to_timedelta(df['列名'].astype('float'), unit='D') + pd.to_datetime('1900-01-01') |
| 複数列まとめて型変換 |
df.astype({'列名1': '型1', '列名2': '型2'}) |
| 全ての列を型変換 |
df.astype('型') |
欠損値の処理
欠損値の有無を確認
| 逆引き |
コマンド |
| 各列ごとの欠損値の数を確認 |
df.isnull().sum() |
欠損値の抽出
| 逆引き |
コマンド |
| 欠損値が1つでもある行を抽出 |
df[df.isnull().any(axis=1)] |
| 指定した1つの列名に欠損値がある行を抽出 |
df[df['列名'].isnull()] |
欠損値の削除
| 逆引き |
コマンド |
| 欠損値が1つでもある行を削除 |
df.dropna() |
| 指定した列に欠損値がある行を削除 |
df.dropna(subset=[列名のリスト]) |
欠損値の置換
| 逆引き |
コマンド |
| 全ての列に対して共通の値で置換 |
df.fillna('値') |
| 列ごとに異なる値で置換 |
df.fillna({'列名1': 値1, '列名2': 値2}) |
外れ値の確認
定性データ(質的変数)
| 逆引き |
コマンド |
| 指定した列の一意な値のリストを確認 |
df['列名'].unique() |
| 指定した列の一意な値の出現回数を確認 |
df['列名'].values_count() |
定量データ(量的変数)
| 逆引き |
コマンド |
| 有効データ数、平均値、標準偏差、最小値、四分位数(25%点、50%点、75%点)、最大値を確認 |
df.describe() |
時系列データ(日時型)
| 逆引き |
コマンド |
| 最初の日付を確認 |
df['列名'].min() |
| 最後の日付を確認 |
df['列名'].max() |
データ抽出
直接抽出
行を抽出する
| 逆引き |
コマンド |
戻り値 |
| 先頭5行を抽出 |
df.head() |
pd.DataFrame |
| 末尾5行を抽出 |
df.tail() |
pd.DataFrame |
| 1つの行名に一致する行を抽出 |
df.loc['行名'] |
pd.Series |
| 複数の行名に一致する行を抽出 |
df.loc[['行名1', '行名2']] |
pd.DataFrame |
| 行間のスライスしに一致する行を抽出 |
df.loc['行名1':'行名2'] |
pd.DataFrame |
| ブール値のシリーズに一致する行を抽出 |
df.loc[ブール値のシリーズ] |
pd.DataFrame |
列を抽出する
| 逆引き |
コマンド |
戻り値 |
| 1つの列名に一致する列を抽出 |
df['列名'] |
pd.Series |
| 複数の列名に一致する列を抽出 |
df[['列名1', '列名2']] |
pd.DataFrame |
行と列を抽出する
| 逆引き |
コマンド |
戻り値 |
| 1つの行名と単一の列名 |
df.loc['行名', '列名'] |
strなど |
| 1つの行名と複数の列名 |
df.loc['行名', ['列名1', '列名2']] |
pd.Series |
df.loc[['行名'], ['列名1', '列名2']] |
pd.DataFrame |
| 複数の行名と1つの列名 |
df.loc[['行名1', '行名2'], '列名'] |
pd.Series |
df.loc[['行名1', '行名2'], ['列名']] |
pd.DataFrame |
| 複数の行名と複数の列名 |
df.loc[['行名1', '行名2'], ['列名1', '列名2']] |
pd.DataFrame |
| ブール値のシリーズと1つの列名 |
df.loc[ブール値のシリーズ, '列名'] |
pd.Series |
df.loc[ブール値のシリーズ, ['列名']] |
pd.DataFrame |
| ブール値のシリーズと複数の列名 |
df.loc[ブール値のシリーズ, ['列名1', '列名2']] |
pd.DataFrame |
条件抽出
数値比較(比較演算子)
| 逆引き |
コマンド |
戻り値 |
| 一致 |
df.query('列名==数値') |
pd.DataFrame |
df[df['列名']==数値] |
pd.DataFrame |
| 未満 |
df.query('列名<数値') |
pd.DataFrame |
df[df['列名']<数値] |
pd.DataFrame |
| 以下 |
df.query('列名<=数値') |
pd.DataFrame |
df[df['列名']<=数値] |
pd.DataFrame |
| 超過 |
df.query('列名>数値') |
pd.DataFrame |
df[df['列名']>数値] |
pd.DataFrame |
| 以上 |
df.query('列名>=数値') |
pd.DataFrame |
df[df['列名']>=数値] |
pd.DataFrame |
| 以外 |
df.query('列名!=数値') |
pd.DataFrame |
df[df['列名']!=数値] |
pd.DataFrame |
文字列比較
| 逆引き |
コマンド |
戻り値 |
| 完全一致 |
df.query('列名=="文字列"') |
pd.DataFrame |
df[df['列名']=="文字列"] |
pd.DataFrame |
| 前方一致 |
df.query('列名.str.startswith("文字列")', engine='python') |
pd.DataFrame |
df[df['列名'].str.startswith('文字列', na=False)] |
pd.DataFrame |
| 後方一致 |
df.query('列名.str.endswith("文字列")', engine='python') |
pd.DataFrame |
df[df['列名'].str.endswith('文字列', na=False)] |
pd.DataFrame |
| 部分一致 |
df.query('列名.str.contains("文字列")', engine='python') |
pd.DataFrame |
df[df['列名'].str.contains('文字列', na=False)] |
pd.DataFrame |
| 正規表現一致 |
df.query('列名.str.match(r"正規表現")', engine='python') |
pd.DataFrame |
df[df['列名'].str.match(r'正規表現', na=False)] |
pd.DataFrame |
論理演算子
| 逆引き |
コマンド |
戻り値 |
| AND(論理積) |
df.query('条件式1&条件式2') |
pd.DataFrame |
df[(ブール値のシリーズ1)&(ブール値のシリーズ2)] |
pd.DataFrame |
| OR(論理和) |
df.query('条件式1|条件式2') |
pd.DataFrame |
df[(ブール値のシリーズ1)|(ブール値のシリーズ2)] |
pd.DataFrame |
| NOT(補集合) |
df.query('~条件式') |
pd.DataFrame |
df[~(ブール値のシリーズ)] |
pd.DataFrame |
欠損値の抽出
| 逆引き |
コマンド |
戻り値 |
| 欠損値が1つでもある行 |
df[df.isnull().any(axis=1)] |
pd.DataFrame |
| 指定した1つの列名に欠損値がある行 |
df[df['列名'].isnull()] |
pd.DataFrame |
重複値の抽出
| 逆引き |
コマンド |
戻り値 |
| すべての値が重複している行 |
df[df.duplicated()] |
pd.DataFrame |
| 指定した列で値が重複している行 |
df[df.duplicated(subset=[列名のリスト])] |
pd.DataFrame |
| 指定した列で重複していない行 |
df[~df.duplicate(subset=[列名のリスト])] |
pd.DataFrame |
ランダムサンプリング
pandas.DataFrame.sample
| 逆引き |
コマンド |
戻り値 |
| ランダムに1行 |
df.sample() |
pd.DataFrame |
| ランダムに30行 |
df.sample(n=30) |
pd.DataFrame |
| ランダムに30%行 |
df.sample(frac=0.3) |
pd.DataFrame |
| ランダムに30行(重複抽出を許可) |
df.sample(n=30, replace=True) |
pd.DataFrame |
| ランダムに30%行(乱数値を固定) |
df.sample(frac=0.3, random_state=0) |
pd.DataFrame |
ホールドアウトセット
sklearn.model_selection.train_test_split — scikit-learn 0.23.1 documentation
構文
from sklearn.model_selection import train_test_split
Xdf = df.drop(columns='目的変数の列名') # 特徴量
ydf = df['目的変数の列名'] # 目的変数
Xtrain, Xtest, ytrain, ytest = train_test_split(
Xdf, # 第1引数、特徴量の2次元配列 : arr_2d, np.ndarray, pd.DataFrame, sp.sparse
ydf, # 第2引数、目的変数の1次元配列 : arr_2d, np.ndarray, pd.DataFrame, sp.sparse
test_size=0.3, # テスト用データのサイズ。Noneの場合、train_sizeの補数 : float, default=0.25
train_size=None, # 学習用データのサイズ。Noneの場合、test_sizeの補数 : float, default=None
random_state=1, # 乱数値を固定 : int, default=None
)
# Returns:
# Xtrain : 学習用データの特徴量マトリックス。DataFrame
# Xtest : テスト用データの特徴量マトリックス。Series
# ytrain : 学習用データの目的変数の配列。DataFrame
# ytest : テストデータの目的変数の配列。Series
データ操作
インデックス
行のインデックス
| 逆引き |
コマンド |
| 行のインデックスを取得 |
df.index |
| 行のインデックスを上書きする |
df.index = ['同じ要素数のリスト'] |
| 列を行のインデックスにセット |
df.index = df.set_index('列名') |
| 行のインデックスを振り直す |
df.index = df.reset_index(drop=True) |
| 行名を変更する |
df.rename(index={'行名1':'新しい行名1', '行名2':'新しい行名2'}) |
列のインデックス(ヘッダー)
| 逆引き |
コマンド |
| 列のインデックスを取得 |
df.columns |
| 列のインデックスを上書きする |
df.columns = ['同じ要素数のリスト'] |
| 列名を変更する |
df.rename(columns={'列名1':'新しい列名1', '列名2':'新しい列名2'}) |
キャスト(型変換)
| 逆引き |
コマンド |
| 整数型に型変換 |
s.astype('int') |
| 浮動小数点型に型変換 |
s.astype('float') |
| 文字型に型変換 |
s.astype('str') |
| ブール型に型変換 |
s.astype('bool') |
| Pythonオブジェクト型に型変換 |
s.astype('object') |
| 文字型から日時型に型変換 |
pd.to_datetime(s) |
| シリアル値から日時型に型変換 |
pd.to_timedelta(s.astype('float'), unit='D') + pd.to_datetime('1900-01-01') |
| 複数列まとめて型変換 |
df.astype({'列名1': '型1', '列名2': '型2'}) |
| 全ての列を型変換 |
df.astype('型') |
並び替え
インデックスを基準
| 逆引き |
コマンド |
| 行名で昇順ソート |
df.sort_index() |
| 行名で降順ソート |
df.sort_index(ascending=False) |
| 辞書で行名を昇順ソート |
df['order'] = df.index.map({'行名1': 1, '行名2': 2, …})
df.sort_values(by=['order']).drop(columns=['order']) |
| 列名で昇順ソート |
df.sort_index(axis=1) |
| 辞書で列名を昇順ソート |
df.loc['order'] = df.columns.map({'列名1': 1, '列名2': 2, …})
df.sort_values(by=['order'], axis=1).drop(index=['order']) |
データを基準
| 逆引き |
コマンド |
| 指定した列の値で昇順ソートする |
df.sort_values(by='列名') |
| 指定した列の値で降順ソートする |
df.sort_values(by='列名', ascending=False) |
| 指定した複数の列の値でソートする |
df.sort_values(by=[列名のリスト]) |
| 指定した列の値を辞書でソートする |
df['order'] = df['列名'].map({'値1': 1, '値2': 2, …})
df.sort_values(by='order').drop(columns=['order']) |
削除
| 逆引き |
コマンド |
| 行名を指定して行を削除 |
df.drop(index=[行名のリスト]) |
| 列名を指定して列を削除 |
df.drop(columns=[列名のリスト]) |
| 欠損値が1つでもある行を削除 |
df.dropna() |
| 指定した列に欠損値がある行を削除 |
df.dropna(subset=[列名のリスト]) |
| 指定した列で重複している行を削除 |
df[~df.duplicate(subset=[列名のリスト])] |
置換
| 逆引き |
コマンド |
| 完全一致の辞書で置換 |
s.apply(lambda x: {'検索値': '置換値', …}.get(x, x)) |
| 正規表現に一致した箇所を置換 |
s.astype('str').str.replace(r'正規表現', '置換値') |
| ブール値のシリーズに一致したら値を代入 |
df.loc[ブール値のシリーズ, '列名'] = '値' |
結合
ユニオン(縦方向)
| 逆引き |
コマンド |
| データフレーム同士を縦方向に結合 |
pd.concat([df1, df2], ignore_index=True) |
ジョイン(横方向)
| 逆引き |
コマンド |
| 列名を基準にデータフレーム同士を横方向に結合 |
pd.merge(left=df1, right=df2, on=[列名のリスト], how='left') |
| 行名を基準にデータフレーム同士を横方向に結合 |
pd.merge(left=df1, right=df2, left_index=True, right_index=True) |
| 行名(右)と列名(左)を基準にデータフレーム同士を横方向に結合 |
pd.merge(left=df1, right=df2, left_on='列名', right_index=True) |
| 行名(左)と列名(右)を基準にデータフレーム同士を横方向に結合 |
pd.merge(left=df1, right=df2, left_index=True, right_on='列名') |
集計(要約統計量)
| 逆引き |
コマンド |
戻り値 |
| データフレームの要約統計量 |
df.describe() |
pd.DataFrame |
| シリーズの有効データ数 |
s.count() |
int |
| シリーズの一意な値の数 |
s.nunique() |
int |
| シリーズの有効データの合計値 |
s.astype('float').sum() |
float |
| シリーズの有効データの平均値 |
s.astype('float').mean() |
float |
| シリーズの有効データの中央値 |
s.astype('float').median() |
float |
| シリーズの有効データの最頻値 |
s.astype('float').mode() |
pd.Series |
| シリーズの有効データの最小値 |
s.astype('float').min() |
float |
| シリーズの有効データの最大値 |
s.astype('float').max() |
float |
| シリーズの有効データの不偏歪度 |
s.astype('float').skew() |
float |
| シリーズの有効データの不偏尖度 |
s.astype('float').kurt() |
float |
| シリーズの有効データの不偏標準偏差 |
s.astype('float').std() |
float |
| シリーズの有効データの不偏標準誤差 |
s.astype('float').sem() |
float |
集約(groupby、pivot_table)
1つの定性データの列をグルーピング

1つの定性データの列をグルーピングし、その他の定量データの列にさまざまな集約関数を適用する場合は、pandas.DataFrame.groupbyメソッドでグルーピングし、pandas.DataFrame.aggメソッドでまとめて集約関数を適用させます。
pandas.DataFrame.groupby
pandas.DataFrame.agg
構文と使用例
df.groupby(
by='sex', # グルーピングする列名 : column, list of columns
# axis=1, # グルーピングする方向 : {0 or 'index', 1 or 'columns'}, default 0
# as_index=False, # グループラベルをインデックスにする : bool, default True
).agg(
{'age': ['min', 'median', 'max']} # 列名と集約関数の1次元配列でマッピングされた辞書
)
# Returns:
# DataFrame
aggメソッドで使える集約関数
| 逆引き |
集約関数 |
| データ数 |
'size' |
| 有効データ数 |
'count' |
| 有効データのユニーク値の数 |
'nunique' |
| 合計値 |
'sum' |
| 最小値 |
'min' |
| 最大値 |
'max' |
| 平均値 |
'mean' |
| 中央値 |
'median' |
| 最頻値 |
pd.Series.mode |
| 不偏歪度 |
'skew' |
| 不偏尖度 |
pd.Series.kurt |
| 不偏標準偏差 |
'std' |
| 不偏標準誤差 |
'sem' |
2つの定性データの列をグルーピング(ダイナミッククロス集計)
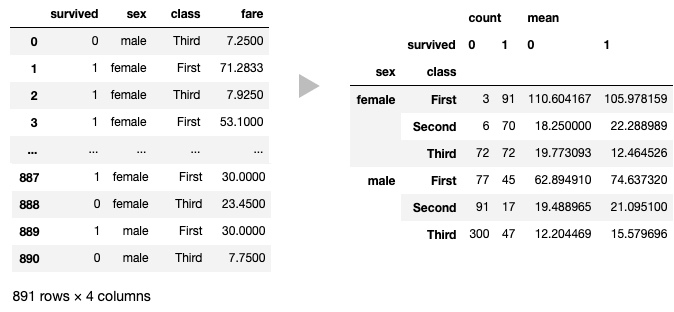
2つの定性データの列をグルーピングし、その他の定量データの列にさまざまな集約関数を適用しダイナミッククロス集計を行う場合は、pandas.DataFrame.pivot_tableメソッドを使用します。
pandas.DataFrame.pivot_table
構文と使用例
df.pivot_table(
index=['sex', 'class'], # グルーピングする列名(行) : column, list of columns
columns='survived', # グルーピングする列名(列) : column, list of columns
values='fare', # 集約関数を適用する列名 : column, list of columns
aggfunc=['count', np.mean], # 集約関数 : function, list of functions, default np.mean
# fill_value=0, # 集計後の欠損値を指定した値で穴埋め : scalar, default None
# margins=True, # カテゴリごとの小計・総計を算出 : bool, default False
# margins_name='All', # 小計・総計のラベル名を変更 : str, default 'All'
)
# Returns:
# Excel形式のピボットテーブル。DataFrame
aggfuncパラメータで使える集約関数
| 逆引き |
集約関数 |
| データ数 |
np.size |
| 有効データ数 |
'count', pd.Series.count |
| 有効データのユニーク値の数 |
pd.Series.nunique |
| 合計値 |
'sum', np.sum |
| 最小値 |
'min', np.min |
| 最大値 |
'max', np.max |
| 平均値 |
'mean', np.mean |
| 中央値 |
'median', np.median |
| 最頻値 |
pd.Series.mode |
| 不偏歪度 |
'skew', pd.Series.skew |
| 不偏尖度 |
pd.Series.kurt |
| 不偏標準偏差 |
'std', pd.Series.std |
| 不偏標準誤差 |
'sem', pd.Series.sem |
文字列メソッド
時系列メソッド
ビニング

ビニング処理とは、連続する定量データを任意の境界値でセグメントし、定性データへとカテゴリ分けして離散値に変換する処理のことをいいます
MEMO
例えば11歳、24歳をそれぞれ10代、20代のように、年齢を
年齢幅に変更するなどです。
pandasでビニング処理を行う場合、pandas.cutメソッドを使います
pandas.cut — pandas 1.0.3 documentation
構文と使用例
df['generation'] = pd.cut(
x=df['age'],
bins=[-1, 17, 24, 34, 44, 54, 64, df['age'].max()], # 要素数で等分割または境界値を指定して分割 : int, sequence of scalars
labels=['0-17', '18-24', '25-34', '35-44', '45-54', '55-64', '65-'] # 返されるビンのラベルを指定 : array or False, default None
# right= False, # 左右どちらのエッジを含めるか指定 : bool, default True
# retbins=True, # 境界値のリストを返すかどうか : bool, default False
)
# Returns:
# out : ビニング処理されたシリーズ。Categorical, Series, or ndarray
# bins : 境界値のリスト(retbins=Trueの場合のみ)。numpy.ndarray or IntervalIndex
スケール変換(正規化/標準化)
機械学習で桁数の異なるデータをまとめて扱うときは、スケール変換を行います。
しかし、pandasには定量データを直接『正規化』または『標準化』する関数は用意されていません。そこで、scikit-learnモジュールを使用した方法を紹介します。
正規化
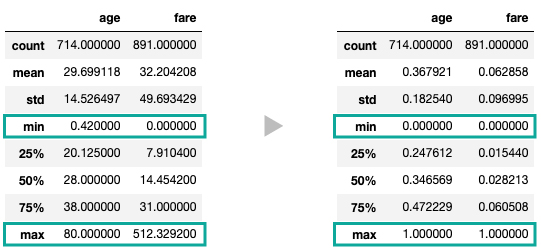
定量データの特徴量を0から1の範囲にスケール変換する正規化は、sklearn.preprocessing.MinMaxScalerメソッドで行います。
sklearn.preprocessing.MinMaxScaler — scikit-learn 0.23.1 documentation
使用例
from sklearn import preprocessing as pp
# 正規化する
scaler = pp.MinMaxScaler()
df[['age', 'fare']] = scaler.fit_transform(df[['age', 'fare']])
# 要約統計量を表示
print(df[['age', 'fare']].describe().to_markdown())
# | | age | fare |
# |:------|-----------:|------------:|
# | count | 714 | 891 |
# | mean | 0.367921 | 0.0628584 |
# | std | 0.18254 | 0.0969951 |
# | min | 0 | 0 | <--
# | 25% | 0.247612 | 0.0154401 |
# | 50% | 0.346569 | 0.0282127 |
# | 75% | 0.472229 | 0.060508 |
# | max | 1 | 1 | <--
標準化
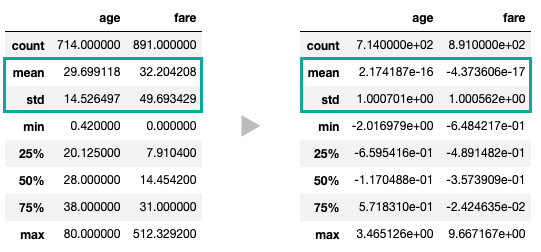
定量データの特徴量を平均0、標準偏差1にスケール変換する標準化は、sklearn.preprocessing.StandardScalerメソッドで行います。
sklearn.preprocessing.StandardScaler — scikit-learn 0.23.1 documentation
使用例
from sklearn import preprocessing as pp
# 標準化する
scaler = pp.StandardScaler()
df[['age', 'fare']] = scaler.fit_transform(df[['age', 'fare']])
# 要約統計量を表示
print(df[['age', 'fare']].describe().to_markdown())
# | | age | fare |
# |:------|--------------:|--------------:|
# | count | 714 | 891 |
# | mean | 2.17419e-16 | -4.37361e-17 | <--
# | std | 1.0007 | 1.00056 | <--
# | min | -2.01698 | -0.648422 |
# | 25% | -0.659542 | -0.489148 |
# | 50% | -0.117049 | -0.357391 |
# | 75% | 0.571831 | -0.0242464 |
# | max | 3.46513 | 9.66717 |
ダミー変数化
マルチインデックス

