
こんにちは、データサイエンティストのたぬ(@tanuhack)です!
質の高いアウトカム(因果関係の推察、未来の予測)を実現するためには、モデリングにかける前のデータの質が大切になってきます。
『データの質を上げる』とは、モデリングの精度を上げることであり、その精度を上げるためにはデータの整形すなわち『前処理』が大切です。
データ分析の8割は、前処理だと言っても過言ではないでしょう。つまり、この泥臭い前処理を怠らず分析の精度の質を高めていくことこそが、データ分析する人の使命であり、力量が試されます。
この記事で取り扱う範囲は、以下の赤文字の部分です。
- 解決したい問題がある
- モジュールのインポート・データを取り込む
- データの状態を確認する(基本情報や欠損値、基本統計量を確認したり、データを可視化して仮説を立てやすくしたり、など)
- データの抽出・整形(※前処理のメイン)
- モデリング
- 分析結果の報告
Pythonという手段を用いて、データの前処理をする場合、主にPandasモジュールを多用します。
そこで今回は、Pandasでの前処理を分かりやすくするために、実際のデータに関数を当てはめ、論理的にも直感的にも分かりやすくしてみました。
データセットは、SIGNATE(シグネイト)と呼ばれる日本版kaggleの勉強用に提供されているお弁当の需要予測データを使用します。
前置きが長くなりました。それでは、どうぞ
[aside]補足この記事は随時更新されるものなので、たまに覗くと内容がアップデートされていていると思います![/aside]

データサイエンティスト / ブロガー
たぬ
tanu
福岡在住のデータサイエンティスト。Pythonでルーチンワークを瞬殺する仕組みを作ることやデータを視覚化することが得意です。
初期設定
モジュールをインポート
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline # jupyter内に描画
import seaborn as sns # pip install seaborn
sns.set(font='IPAexGothic')seabornはmatplotlibのラッパー的存在で、sns.set(font='IPAexGothic')という設定によって、グラフの見た目をseaborn(いい感じ)にして、日本語フォントにも対応させることができます。
jupyter notebookの設定
# Retina用の高解像度出力
%config InlineBackend.figure_formats = {'png', 'retina'}# 常に全てのカラムを表示する
pd.set_option('display.max_columns', None)# 表示用の有効桁数を2にする
pd.options.display.precision=2# プログレスバー(ループの進捗確認)を表示させる
from tqdm import tqdm_notebook as tqdm
# ループの処理
for index, item in tqdm(enumerate(['1次元配列'])):データを読み込む
CSVファイル/TXTファイル
Pandasのread_csvメソッドを用いて、CSVファイルまたはTXTファイルを読み込みます。
デフォルトでは、CSVファイルが読み込まれますが、sep='\t'オプションを追加すると、TXTファイルを読み込むことができます。read_csvメソッドのその他のオプションは、以下の表で確認してください。
| 引数 | 説明 |
|---|---|
encoding='cp932またはUTF-8' |
セルに日本語が含まれている場合、必須 |
header=None |
先頭行をカラムとして取り込みたくないときに使う |
dtype='object' |
すべてのセルを『文字列』として取り込む |
names='リストまたはタプル' |
任意のカラム名を設定する |
sep='\t' |
TXTファイルを読み込む |
1つのファイルを読み込む
df = pd.read_csv('csvファイルのディレクトリ')複数のファイルをまとめて読み込む
from glop import glob
csv_files_dir = glob('*.csv') # 『*』がワールドカード
marge_csv = []
for f in csv_files_dir:
marge_csv.append(pd.read_csv(f, encoding='文字コード'))
# 1つのデータフレームに結合する
# ignore_index=Trueでインデックスをリセット
df = pd.concat(marge_csv, ignore_index=True) 【Python】PandasでCSVファイルを読み込み/書き出しする実践テクニック集
【Python】PandasでCSVファイルを読み込み/書き出しする実践テクニック集
EXCELファイル
df = pd.read_excel('EXCELファイルのディレクトリ', sheet_name='シート名')Googleスプレッドシート
import json
import gspread # pip install gspread
from oauth2client.service_account import ServiceAccountCredentials # pip install oauth2client
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name('秘密鍵のJSONファイルのdirパス', scope)
gc = gspread.authorize(credentials)
SPREADSHEET_KEY = 'スプレッドシートキー'
worksheet = gc.open_by_key(SPREADSHEET_KEY).worksheet('ワークシート名')
df = pd.DataFrame(worksheet.get_all_values()) 【もう迷わない】Pythonでスプレッドシートに読み書きする初期設定まとめ
【もう迷わない】Pythonでスプレッドシートに読み書きする初期設定まとめ
 gspreadライブラリの使い方まとめ!Pythonでスプレッドシートを操作する
gspreadライブラリの使い方まとめ!Pythonでスプレッドシートを操作する
 [データI/O]スプレッドシート×DataFrameを一気に変換する方法
[データI/O]スプレッドシート×DataFrameを一気に変換する方法
データベース
PostgreSQL
import psycopg2 # pip install psycopg2
# 接続情報
connection_config = {
'user': 'ユーザー名',
'password': 'パスワード',
'host': 'localhost',
'port': 'ポート番号',
'database': 'データベース名'
}
# データベースに接続する
connection = psycopg2.connect(**connection_config)
df = pd.read_sql(sql='SELECT * FROM <テーブル名>;', con=connection)
以降は、何らかの方法で、
dfという変数にお弁当の需要予測データを格納したものとして進めます。[/aside]
データの状態を確認
このセクションでは、読み込んだデータにどんなデータが含まれているかを数字で確認したり、グラフで可視化して確認します。
データのちら見
# 先頭5行
df.head()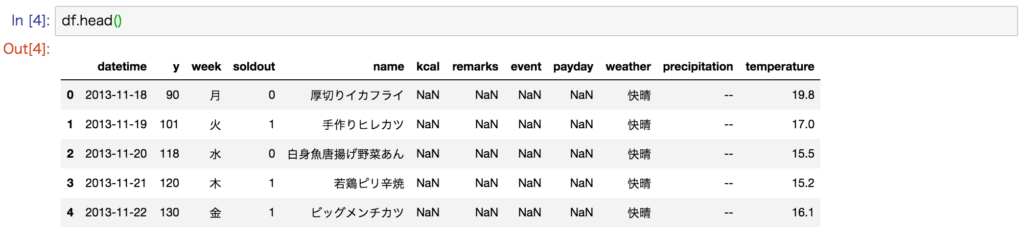
# 末尾5行
df.tail()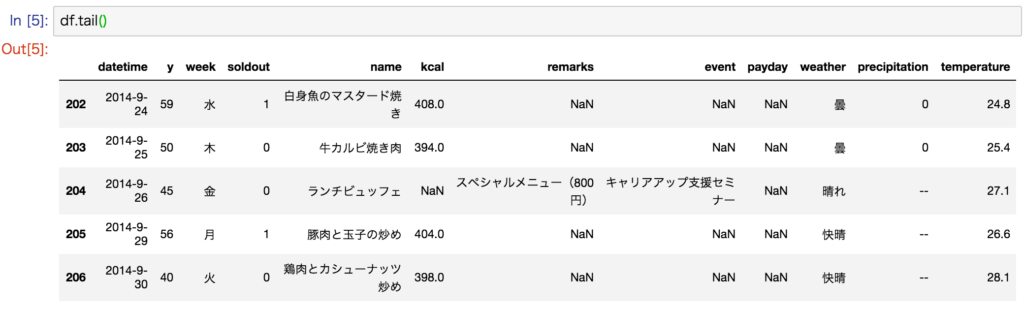
欠損値の確認・処理
Pandasは、通常np.nanで欠損値を表現していて、計算時には基本的に無視されます。
欠損値の確認
# 各列の欠損値の数を調べる
df.isnull().sum()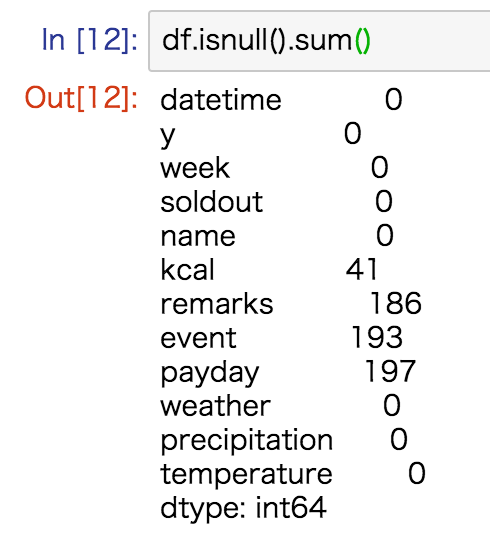
欠損値の処理
# 欠損値がひとつでも含まれている行を削除する
df.dropna()# ある行のすべての値が欠損していたら、その行を削除する
df.dropna(subset=['列名'], how='all')# すべての欠損値を0で置換する
df.fillna(0)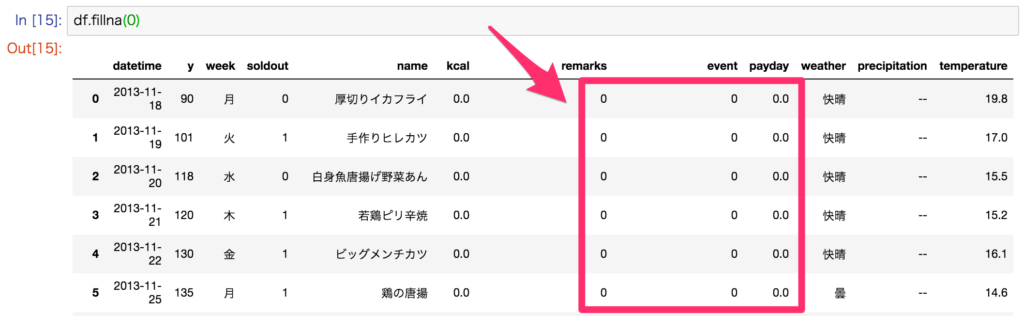
基礎分析
データの構成を確認する
pandas.DataFrameのメソッドinfo()を使うと『有効データ数』や『データ型』、『タイプ』などが一覧で確認出来ます。
df.info()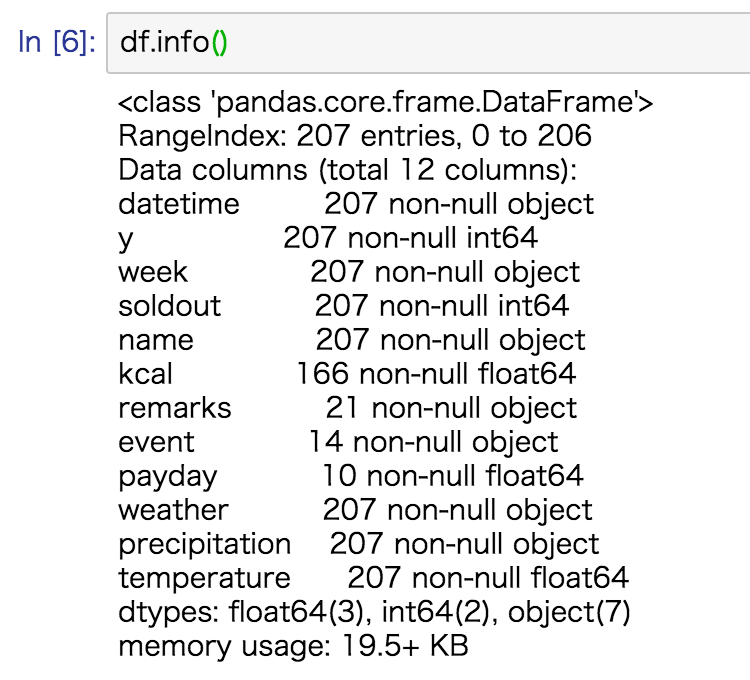
データのサイズを確認する
# 行数と列数を調べる
df.shape
len(df) # 行数だけ
len(df.columns) # 列数だけ
データの行名と列名を確認する
# インデックスとカラムを確認
df.index
df.columns各列にどんな型のデータが含まれているか確認する
# DataFrameの各列のデータ型を確認
df.dtypes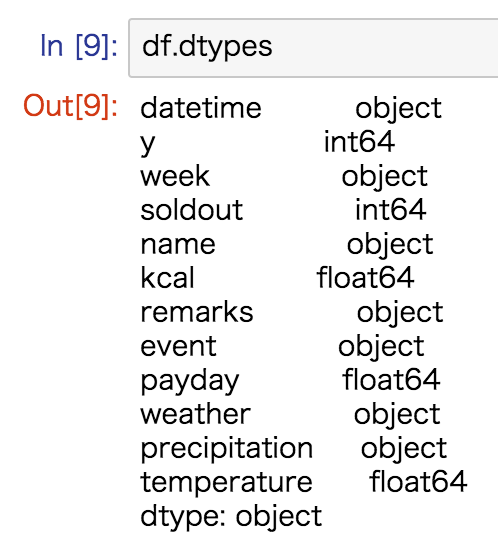
列のユニークな(重複を含まない)値を確認する
# ある列のユニークな値を確認
df['列名'].unique()
列のユニークな値ごとの出現頻度を確認する
# ある列のユニークな値ごとのカウント数を調べる
df['列名'].value_counts()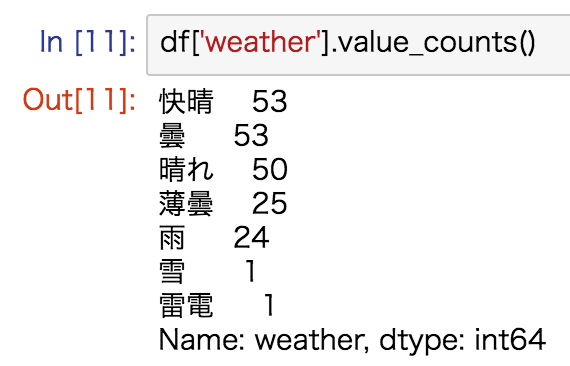
欠損値もカウントさせたい場合は、value_counts(dropna=False)とします。
基本統計量の確認
pandas.DataFrameのメソッドdescribe()を使うと、有効データ数、平均値、不偏標準偏差、最小値、第1四分位数、第2四分位数(=中央値)、第3四分位数、最大値の一覧が確認出来ます。
describe()は量的データの列のみ対応します。
df.describe()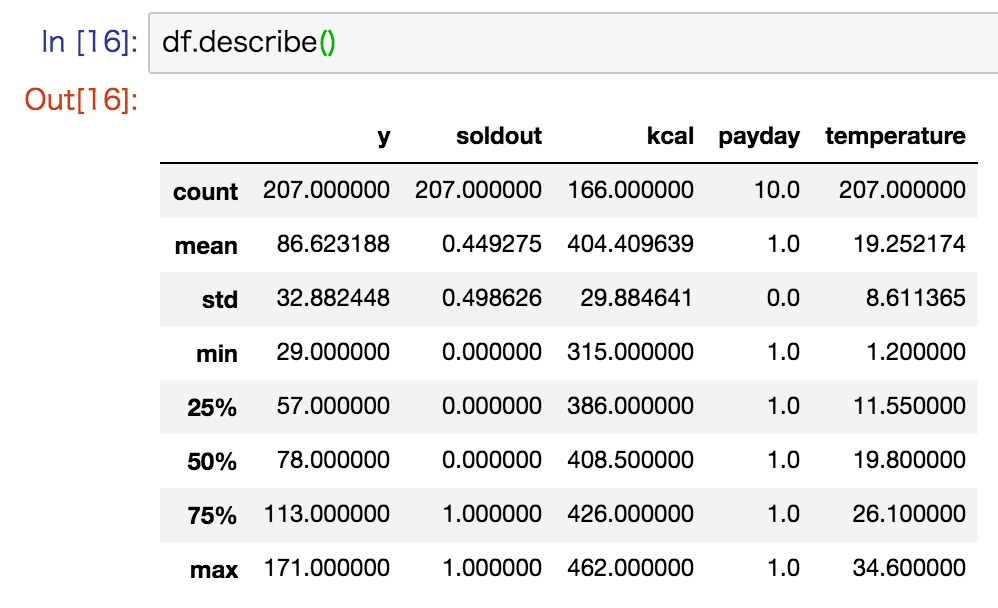
データの可視化
『データ分析するときに使うグラフ』と『分析結果を報告するときに使うグラフ』は違います。
ここではデータの可視化によって、データ全体の傾向を目で確認し、仮説を立てやすくすることに特化したグラフ(すなわち前者)を紹介します。
Pythonには、グラフを描画するモジュール(matplotlibやseaborn、plotlyなど)がたくさん用意されていますが、データ分析者の手間が少なくサッと確認できるものを優先して使います。
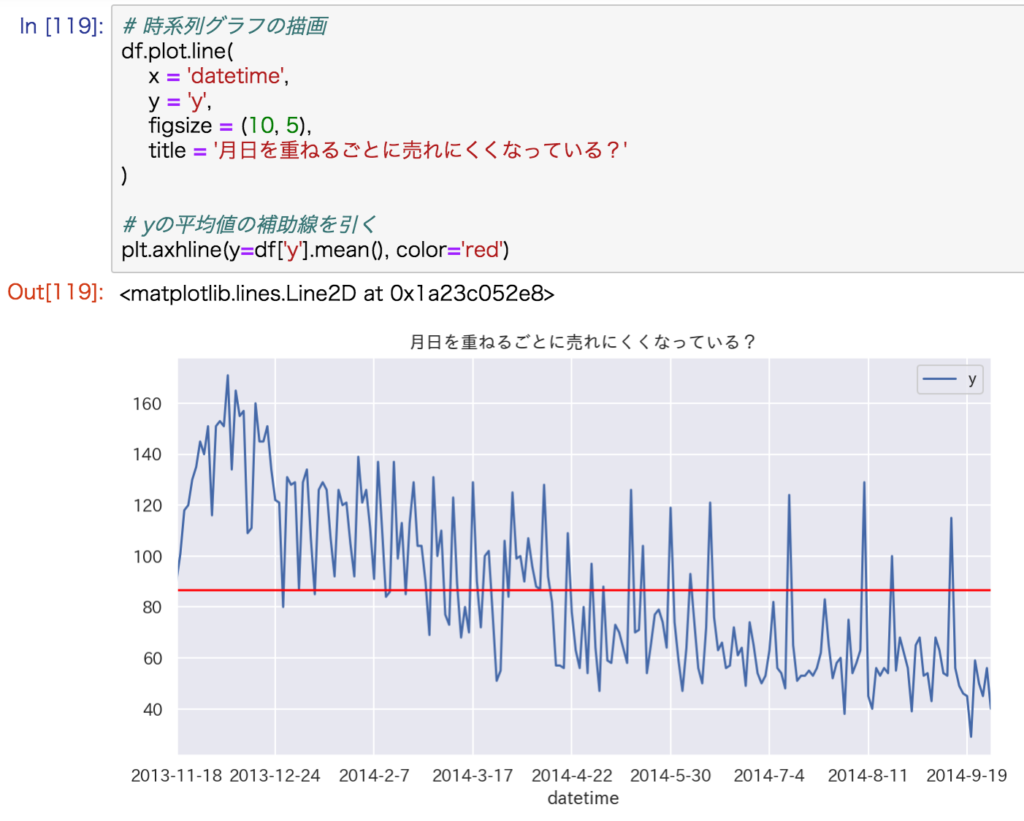
折れ線グラフ
時系列データだった場合、まず時間の経過とともに目的変数がどのように遷移しているか確認します。
折れ線グラフを描画するなら、pandas.DataFrameのメソッドplot.line()がおすすめです。
# 折れ線グラフの描画
df.plot.line(
x = '列名', # 説明変数(X軸)
y = '列名', # 目的変数(Y軸)
figsize = (10, 5), # グラフの大きさ
title = '任意のテキスト' # グラフタイトル
)
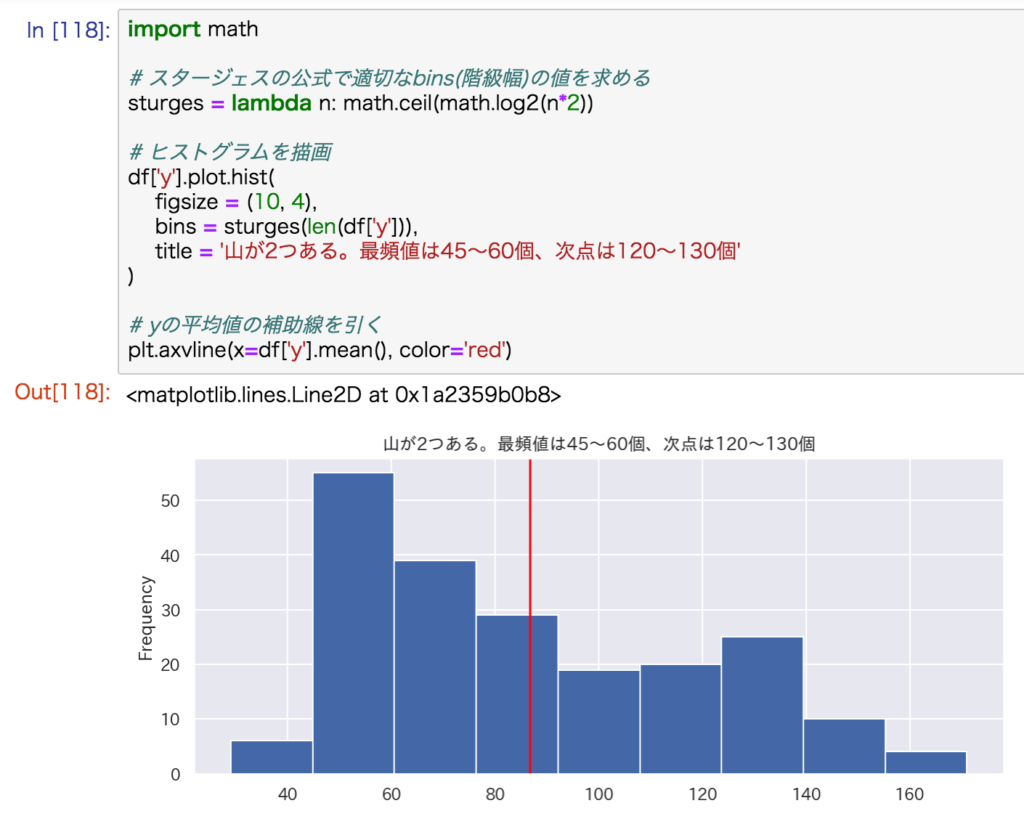
ヒストグラム
1変量データの全体的な『ばらつき具合』を視覚的に確認するときにヒストグラムを使います。
サクッとヒストグラムを描画するなら、pandas.DataFrameのメソッドplot.hist()がおすすめです。
import math
# スタージェスの公式で適切なbins(階級幅)の値を求める
sturges = lambda n: math.ceil(math.log2(n*2))
# ヒストグラムを描画
df['列名'].plot.hist(
bins = sturges(len(df['列名'])), # 階級幅
figsize = (10, 4), # グラフの大きさ
title = '任意のテキスト' # グラフタイトル
)
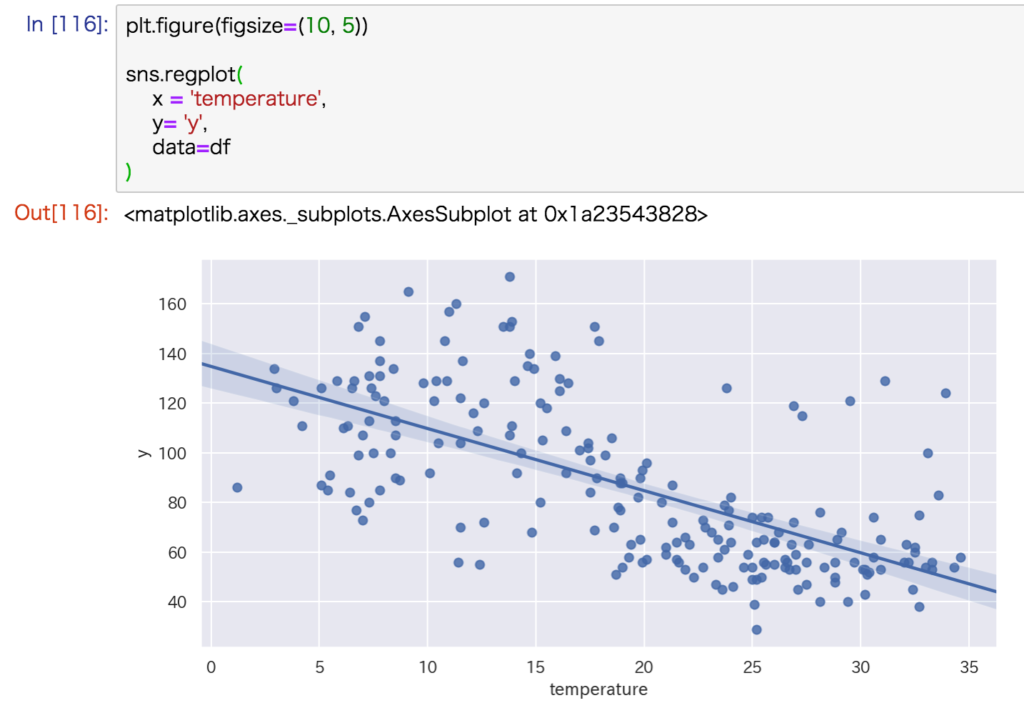
散布図
2変量データ間の関係性を確認するときに使うのが散布図です。
seabornのメソッドregplot()を使うと、散布図といっしょに『回帰直線』も描画してくれます。
# グラフの大きさ
plt.figure(figsize=(10, 5))
# 回帰直線付きの散布図を描画
sns.regplot(
x = '列名', # 説明変数
y = '列名', # 目的変数
data=df
)
散布図とヒストグラムをまとめて描画
seabornのメソッドpairplot()を使うと、各列ごとのヒストグラム・散布図をまとめて描画することができます。
kind='reg'というオプションを追加すると、回帰直線も描画されます。
# 散布図、ヒストグラムをまとめて描画(量的データの列のみ)
sns.pairplot(data=df, kind='reg')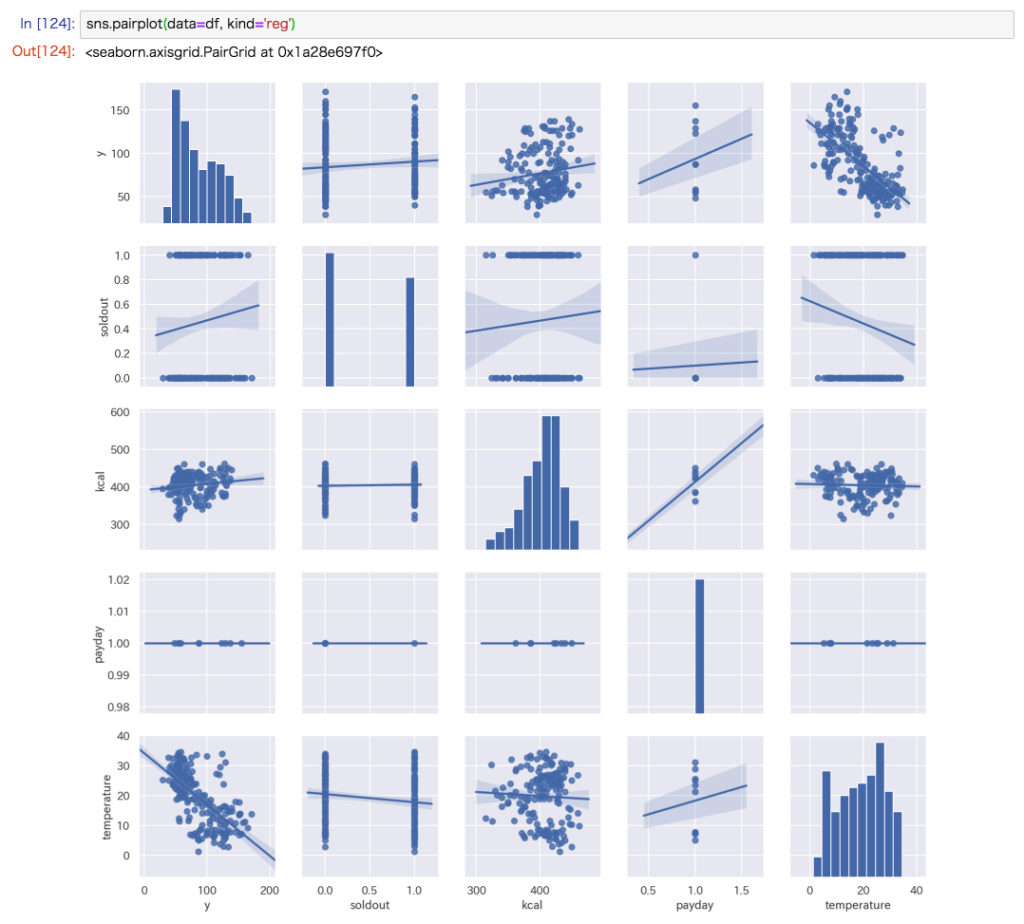
箱ひげ図
pandas.DataFrameのメソッドboxplot()を使います。
df[['説明変数の列名','目的変数の列名']].boxplot(by='説明変数の列名', figsize=(10,5))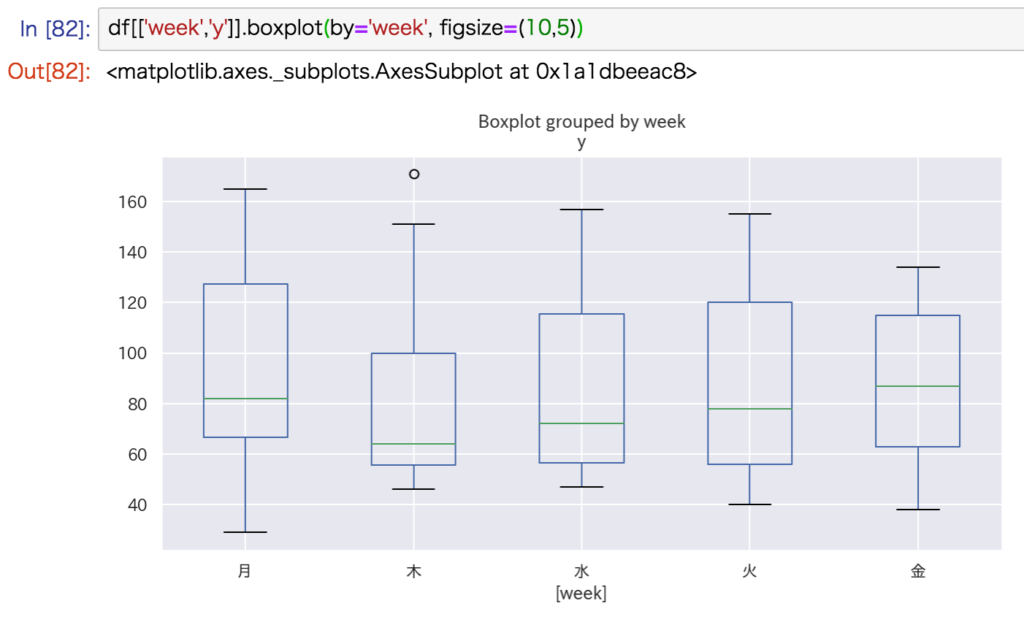
データの選択/抽出
直接指定
単一の列だけ指定
# 列Aを選択
df['A']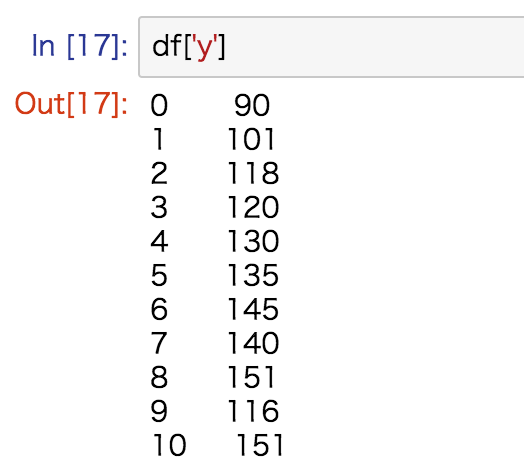
複数の列を指定
# 列A,Bを選択
df[['A', 'B']]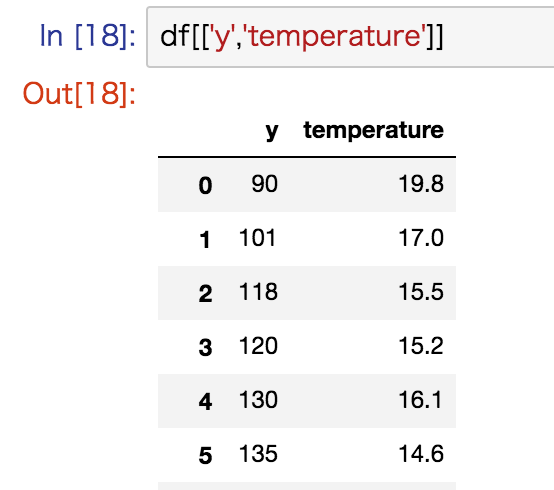
条件指定
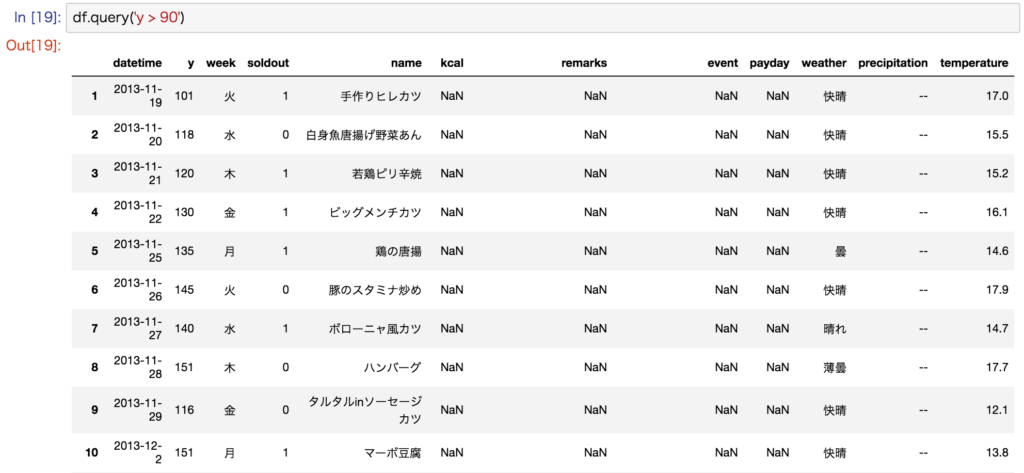
主に、pandas.DataFrameのメソッドquery()を使います。
# 列Aで値がaaのものを選択
df.query('A == "aa"')
# 列Bで値が0以下であるものを選択
df.query('B <= 0')
# 列Aで値がaaかつ列Bで値が0以下であるものを選択
df.query('A == "aa" & B <= 0')
# 変数もOK
age = 20
df.query('c <= @age')
部分一致、正規表現で指定
非常に残念ですが、pandas.DataFrame.query()で部分一致や正規表現は使えません(泣)
# 部分一致選択
df[df['列名'].str.contains('部分一致の文字列')]
# 前方一致選択
df[df['列名'].str.startswith('前方一致の文字列')]
# 後方一致選択
df[df['列名'].str.endswith('後方一致の文字列')]
# 正規表現
df[df['列名'].str.match('正規表現')]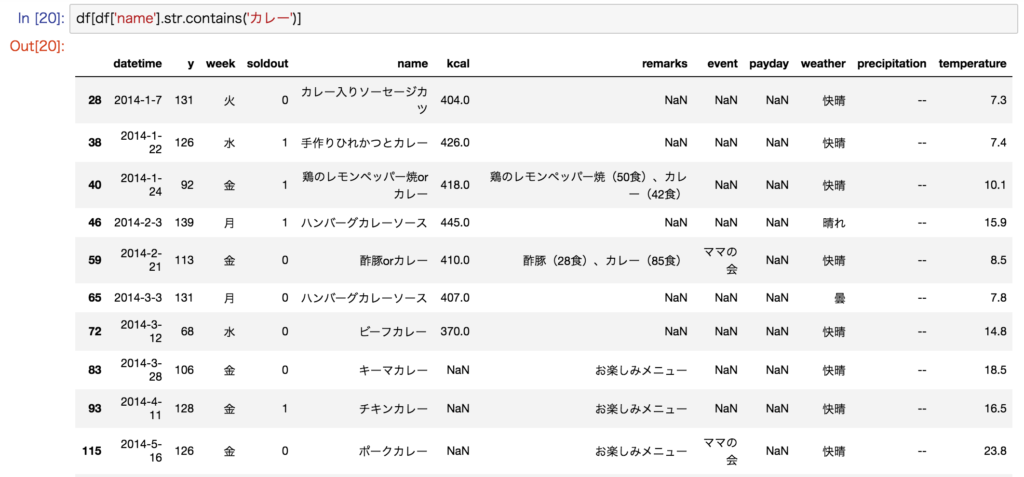
ランダム指定
ランダムサンプリングを行いたい場合は、pandas.DateFrameのメソッドsample()を使用します。
デフォルトでは、ランダム値はプログラムを実行するたびに変更されますが、random_stateというオプションに任意の値を設定することでランダム値を固定できます。
# データを全体の50%の割合でランダム抽出する
df.sample(frac=0.5, random_state=0)
# データを100個ランダム抽出する
df.sample(n=100, random_state=0)
データの整形
集計
# 有効データのカウント数
df['列名'].count()
# 合計値
df['列名'].sum()
# 最小値
df['列名'].min()
# 最大値
df['列名'].max()
# 平均値
df['列名'].mean()
# 中央値
df['列名'].median()
# 最頻値
df['列名'].mode()
# 標本分散
df['列名'].var(ddof=False)
# 不偏分散
df['列名'].var(ddof=True)
# 標本標準偏差
df['列名'].std(ddof=False)
# 不偏標準偏差
df['列名'].std(ddof=True)置換
# A列でaaという値を含むなら、そのセルの値をbbに置換する
df.loc[df['A'].str.contains('aa'), 'A'] = 'bb'削除
行または列の削除
# 行の削除
# [inplace=True]:元のDataFrameを更新する。デフォルトはFalse
df.drop('行番号または行名')
# 列の削除
df.drop('列名', axis=1)
# 複数の行をまとめて削除する場合は、リストまたはタプルで指定する
# 列の場合はaxis=1
df.drop('リストまたはタプル')重複行の削除
df.drop_duplicates()| 引数 | 説明 |
|---|---|
[inplace=True] |
元のDataFrameを更新する。デフォルトはFalse |
[keep='last'] |
最後の値を残す。デフォルトはfirst |
[subset='列名のリスト'] |
指定した列名だけの重複を見る |
ソート(並び替え)
# 行に対して降順でソート
df.sort_values(by='列名、または列名のリスト', ascending=False, inplace=True)
# 列の並び替え
# df.columns ==> 'a', 'b', 'c'
df.loc[:,['a','c','b']]
# df.columns ==> 'a', 'c', 'b'キャスト(型変換)
import numpy as np
df['列名'] = df['列名'].astype(np.int) # 整数型に変換
df['列名'] = df['列名'].astype(np.float) # 浮動小数点型に変換
df['列名'] = df['列名'].astype(object) # オブジェクト型に変換
クロス集計表
# クロス集計する(質的データ×質的データ)
# 第1引数:縦列、第2引数:横列、[margins=True:合計値カラムの表示]
pd.crosstab(df['列名A'], df['列名B'])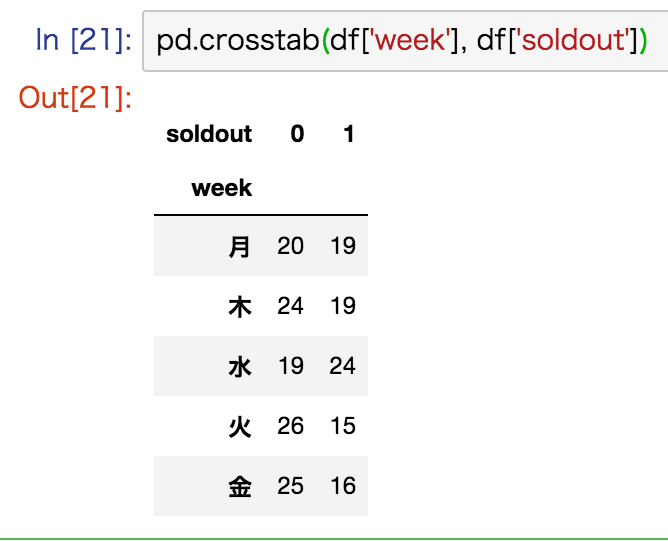
量的データをクロス集計する
# クロス集計する(量的データ×質的データ)
# 量的データはビニング(pd.cut関数)が必要
# cut関数の最初と最後の配列の値は、最小値minより小さく最大値maxより大きい値を設定する
bining = pd.cut(df['A'], [0,10,20,30,40,50]).astype(object) # dtypeをcategory→object
pd.crosstab(bining, df['B'], margins=True)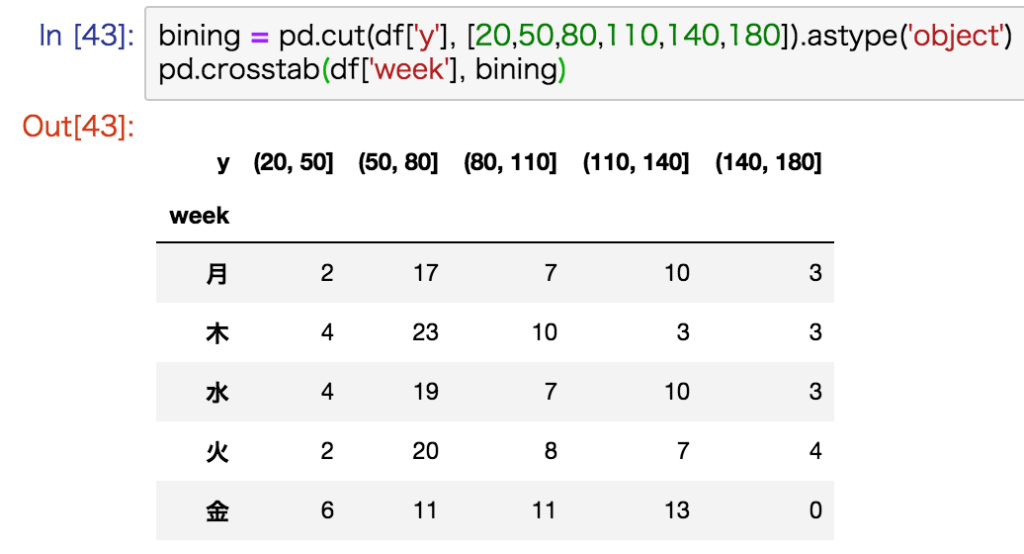
質的データをダミー変数化
適用されるのは質的データだけで、量的データはそのままマージされる
# One-Hotエンコーディングでダミー変数化
pd.get_dummies(df[['列名A','列名B']])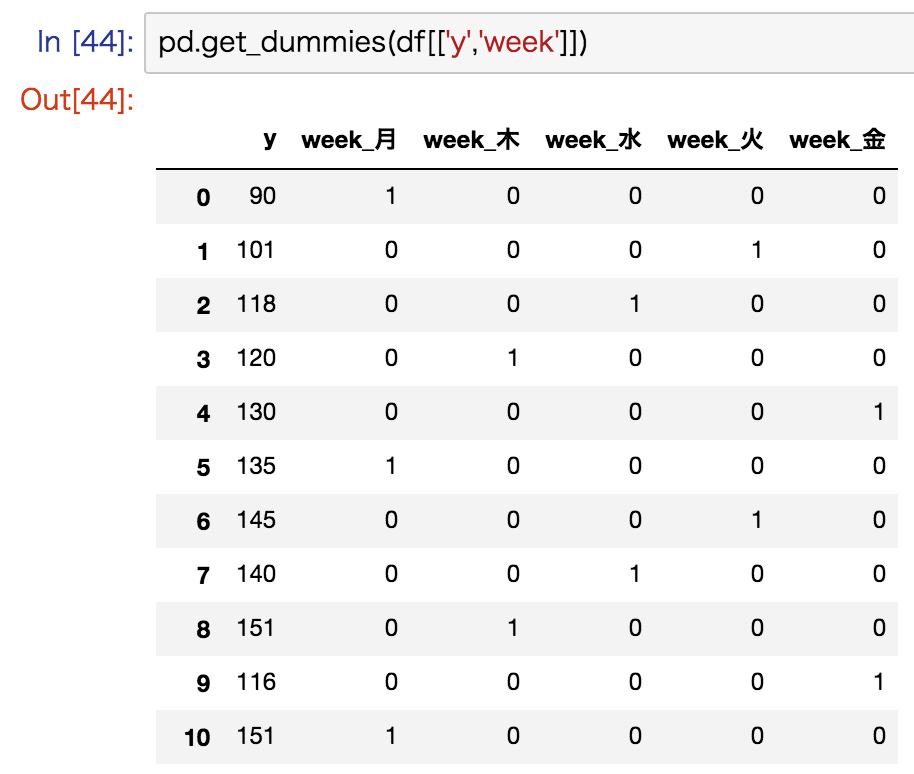
これからのアプローチ
重回帰分析
Pythonで重回帰分析をする方法として、scikit-learnを用いる方法とStatsModelsを用いる方法の2つが存在します。
しかし、scikit-learnを用いる方法では、解析の結果から得られた重回帰式の精度を表す各指標が見れないので使いません。StatsModelsを使いましょう。
import statsmodels.api as sm # pip install statsmodels
import statsmodels.formula.api as smf
# get_dummies()で質的データも対応可能
x = pd.get_dummies(df[['説明変数1', '説明変数2', '説明変数3']])
y = df['目的変数']
# 定数項(y切片)を必要とする線形回帰のモデル式ならば必須
X = sm.add_constant(x)
# 最小二乗法によるモデリング
model = smf.OLS(y, X)
result = model.fit()
# 重回帰分析の結果を表示
result.summary()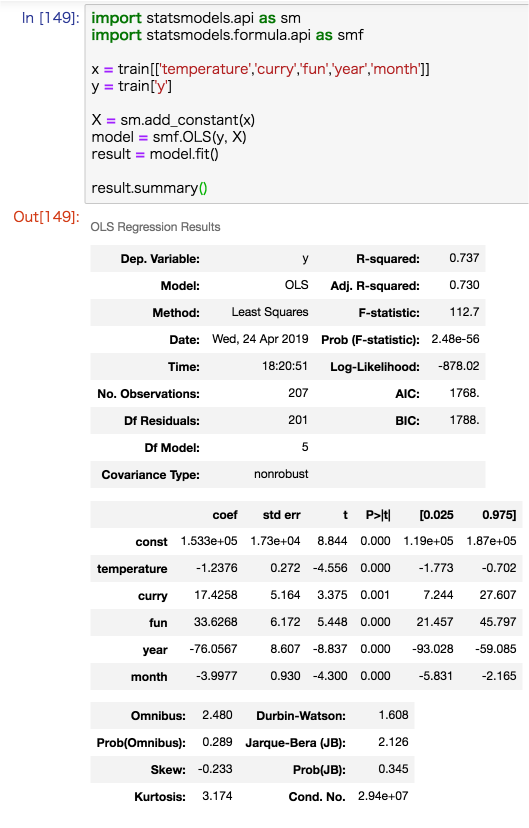
13,000字+20枚の画像で解説しています。
 Python(StatsModels) で重回帰分析を理解し、分析の精度を上げる方法
[/aside]
Python(StatsModels) で重回帰分析を理解し、分析の精度を上げる方法
[/aside]
