
こんにちは、データサイエンティストのたぬ(@tanuhack)です!
僕は普段、Python(PandasのDataFrame)でデータ分析しているので、SQL文を書かずに全部Pythonでやりたいなー思っていました。シームレスだし。
ということで今回は、PostgreSQLからDataFrameに格納したり、DataFrameからPostgreSQLに追加、書き換えしたりする方法を具体例を元に、実践における注意点を踏まえて紹介します。

データサイエンティスト / ブロガー
たぬ
tanu
福岡在住のデータサイエンティスト。Pythonでルーチンワークを瞬殺する仕組みを作ることやデータを視覚化することが得意です。
PostgreSQLの準備
次のコマンドは、記事の理解を深めるために用意した具体例です。
データベースの読み込みと書き出しだけサクッと知りたい方は、この章を読み飛ばしてPostgreSQLを読み込むから読んでくださいね。
$ brew services list$ brew services start postgresql『df-postgres』という名前にデータベースを作成します。
$ createdb df-postgresSTEP.3で作成したデータベースに接続します。
$ psql df-postgres『test』という名前のテーブルを作成します。
- 1列目:id(
int) - 2列目:name(
text)
create table test (id int, name text);insert into test (id, name) values (1,'tanu');
insert into test (id, name) values (2,'hack');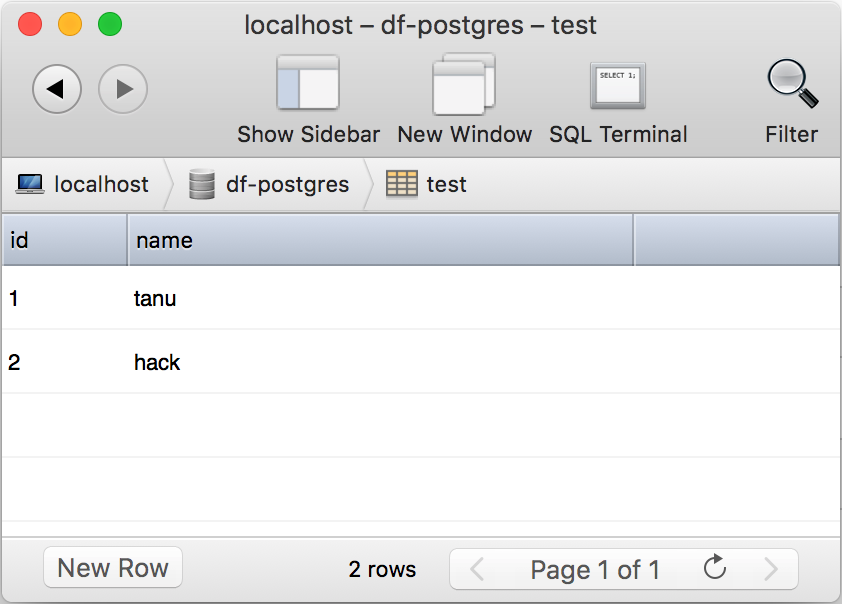
さっそくこのテーブルをPandasのDataFrameに読み込んでみましょう。
PostgreSQLを読み込む
PythonでPostgreSQLを操作するためには、psycopg2モジュールを使用します。
PostgreSQLからデータベースをPandasのDataFrameに格納するためには、pandas.DataFrameのメソッドread_sqlを使用します。
import pandas as pd
import psycopg2
# データベースの接続情報
connection_config = {
'user': 'ユーザー名',
'password': '',
'host': 'localhost',
'port': 'ポート番号', # なくてもOK
'database': 'データベース名'
}
# PostgreSQLに接続する
connection = psycopg2.connect(**connection_config)
# 変数dfにテーブルの全レコードを格納する
df = pd.read_sql(sql='SELECT * FROM テーブル名;', con=connection)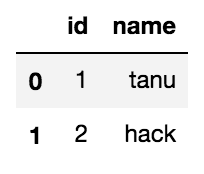
データベースの接続情報がわからなければ、psqlコマンドの\conninfoを叩けば、データベース名・ユーザー名・ポート番号が返り値として得られます。
![]()
PostgreSQLに書き込む
DataFrameの中身をPostgreSQLに書き込むには、pandas.DataFrameのメソッドto_sqlを使用します。
しかし、to_sqlのデフォルトのデータベースはSQLiteになっているので、これをPostgreSQLに変更しないといけません。
そのために、sqlalchemyモジュールからcreate_engineを使用します。
import pandas as pd
from sqlalchemy import create_engine
# データベースの接続情報
connection_config = {
'user': 'ユーザー名',
'password': '',
'host': 'localhost',
'port': 'ポート番号', # なくてもOK
'database': 'データベース名'
}
engine = create_engine('postgresql://{user}:{password}@{host}:{port}/{database}'.format(**connection_config))
# PostgreSQLに書き込む
df.to_sql('テーブル名', con=engine, if_exists='appendまたはreplace', index=False)テーブルに追加する
to_sqlのオプションでif_exists='append'と設定すると、元あるテーブルにDataFrameをPostgreSQLに追加することができます。

# PostgreSQLのテーブルにDataFrameを追加する
df.to_sql('テーブル名', con=engine, if_exists='append', index=False)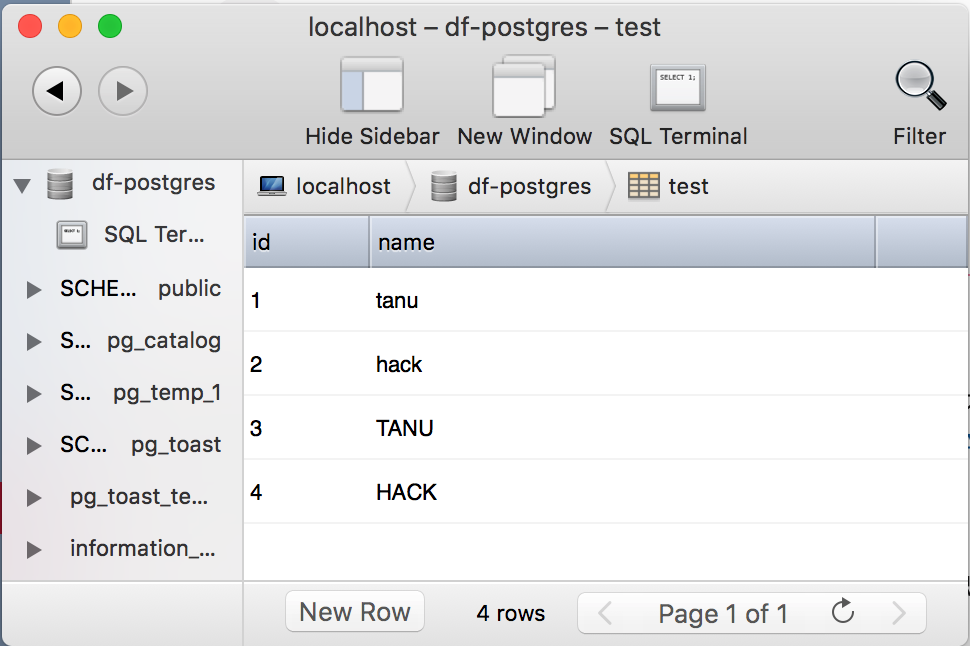
appendするDataFrameのカラムはデータベースと同じ名前、列数にしないとエラーが発生します。
[/aside]
テーブルを上書きする
to_sqlのオプションでif_exists='replace'と設定すると、元あるテーブルに上書きする形でDataFrameをPostgreSQLに格納することができます。
ただ、公式ドキュメントにも記載してあるように、テーブルを上書きする前に元から存在するテーブルを削除しないとエラーが発生します。
if_exists : {‘fail’, ‘replace’, ‘append’}, default ‘fail’. How to behave if the table already exists.
- fail: Raise a ValueError.
- replace: Drop the table before inserting new values.
- append: Insert new values to the existing table.

# テーブルを削除するSQLを実行する
with connection as conn:
with conn.cursor() as cur:
cur.execute('DROP TABLE テーブル名')
# PostgreSQLのテーブルにDataFrameを上書きする
df.to_sql('テーブル名', con=engine, if_exists='replace', index=False)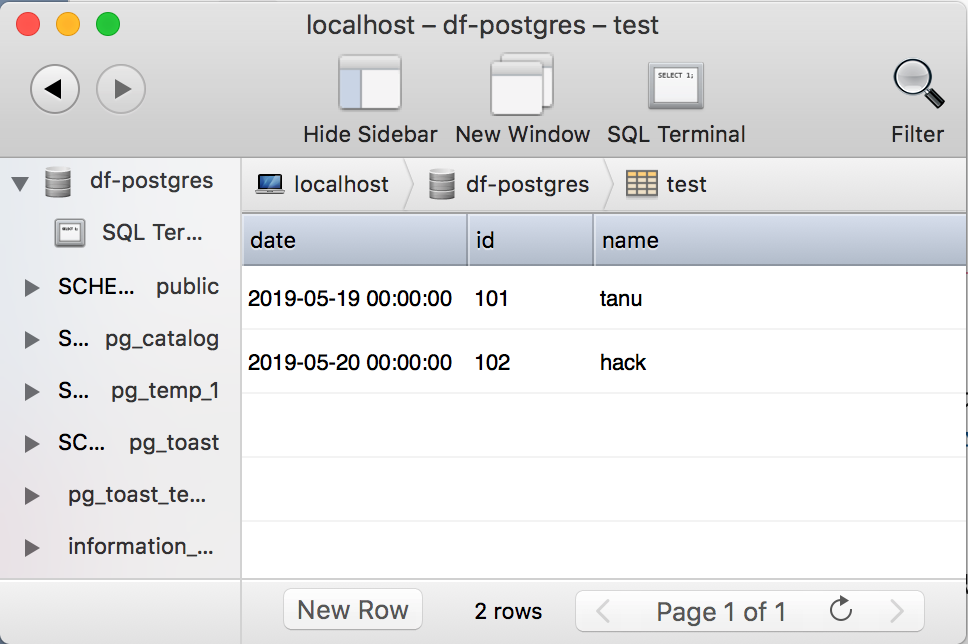
ご覧の通り、上書きされていることが確認できますね。

