
こんにちは、いろんな効率化が大好きなたぬ(@tanuhack)です!
通常、Web上から目当ての情報を取得するときって、目当てのサイトに直接訪れて、情報を手動でGETすると思うんですよね。
今回紹介する『スクレイピング』という技を使えば、なんと、Webサイトに訪れなくても情報を自動でGETすることができます!!!
つまり、PCが決められたルールに従って、勝手に情報を集めて来てくれるという訳です。
本格的なスクレイピングは、高度なプログラミングを要しますが、簡単なスクレイピングであれば、スプレッドシートに用意されている『IMPORTXML』という関数だけで実現することができます。
そこで今回は、IMPORTXML関数を使ったスクレイピングの方法と、実例を7個紹介します!
スクレイピングはサイトによって、禁止されているところもあるので自己責任でお願いします。
目次

データサイエンティスト / ブロガー
たぬ
tanu
福岡在住のデータサイエンティスト。Pythonでルーチンワークを瞬殺する仕組みを作ることやデータを視覚化することが得意です。
IMPORTXMLの使い方
『情報をあつめたいURL』と『どの階層の情報を引き抜くか』を数式に記入するだけです。
たとえば、このサイト(https://tanuhack.com/)のタイトルを取得したいとします。
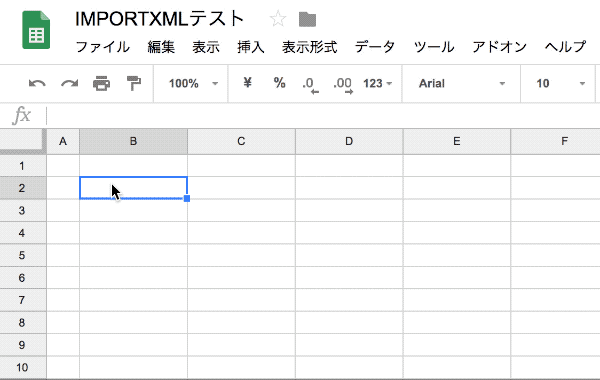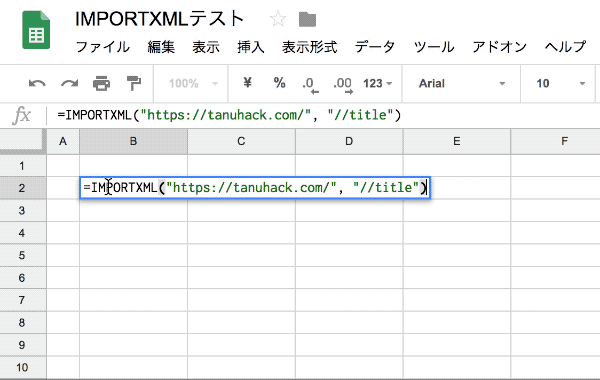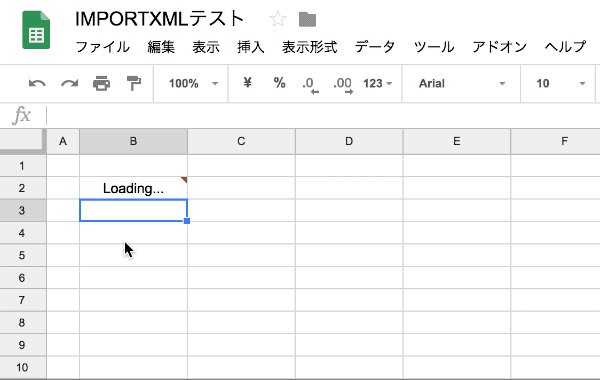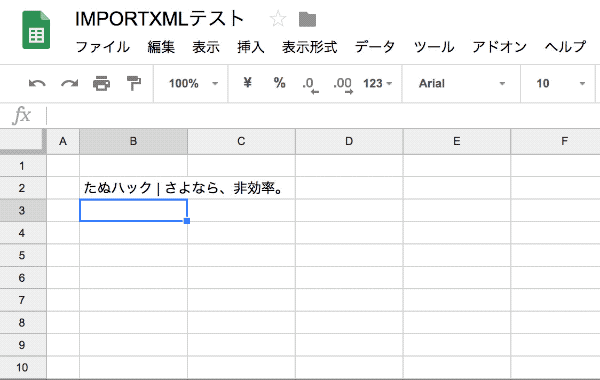
これだけです!たったこれだけで、タイトルを取得することができます!(※IMPORTXMLの値は、2時間毎に更新)
この例では、"//title"の部分がXPathクエリです。
次に、IMPORTXML関数の肝であるXPathについて紹介します。
XPathについて
XPathを使うとHTML文章の中から、さまざまな情報を取得することが出来るようになります。
XPathについて書くとそれだけで記事になってしまうので、割愛します。あしからず。
[aside]下のサイトに詳しくまとめてあったので、XPathについてもっと深く勉強したい方はどうぞ [/aside]でも、ご安心下さい。XPathの記法を知らなくても、Chromeの機能を使えば、難しいXPathの記法を知らなくても、瞬時にXPathを取得することが出来るんですよ!すごいね、Google!
Copy XPath
今回は先程お見せした『たぬハックのタイトルを取得』する作業を実際にお見せしたいと思います。
この方法は、この例にとどまらず、ほぼ全てのWebサイトで有効な手段です。
GIFアニメも用意したので、導入も簡単だと思います!それではどうぞ。
STEP1:Chromeの開発者ツールを開く

- 設定「︙」を選択
- その他のツールを選択
- ディベロッパーツールを選択
または、ショートカットキーを使って呼び出してもいいでしょう。
- Mac:⌘+option+I
- Windows:Ctrl+Shift+Iもしくは、F12
Webに携わる仕事をされている方であれば、開発者ツールを呼び出す機会はよくあると思います。
毎回毎回ポチポチと、設定から開くのではなく、ショートカットキーで瞬時に呼び出した方がスマートでかっこいいです。
STEP2:XPathを取得したい要素を選択

開発者ツールから上の写真のアイコンを選択して、Webページのタイトルを直接選択します。
- Mac:⌘+Shift+C
- Windows:Ctrl+Shift+C
ショートカットキーも用意されています。
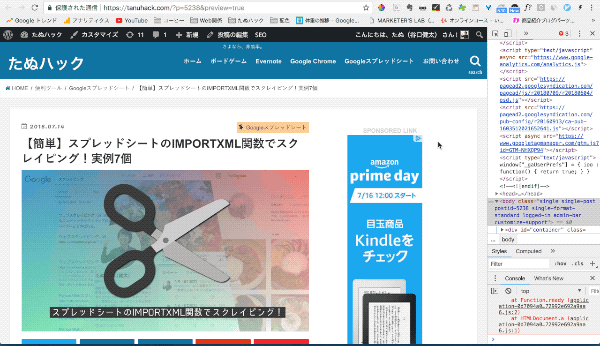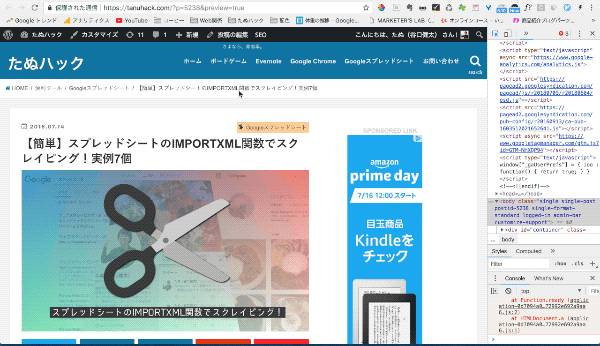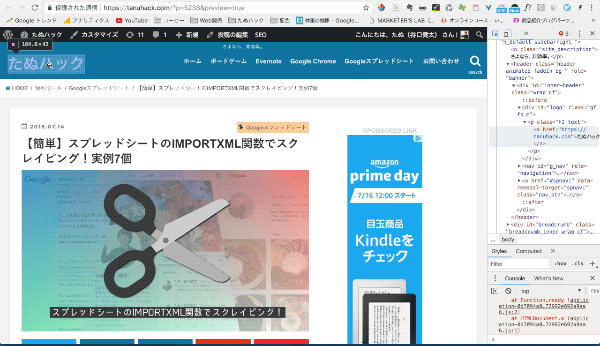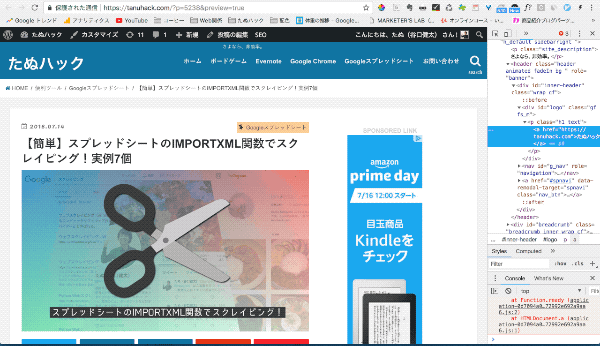
下図のように、右側にあるHTML部分がタイトルの1行だけ選択されていればOKです。
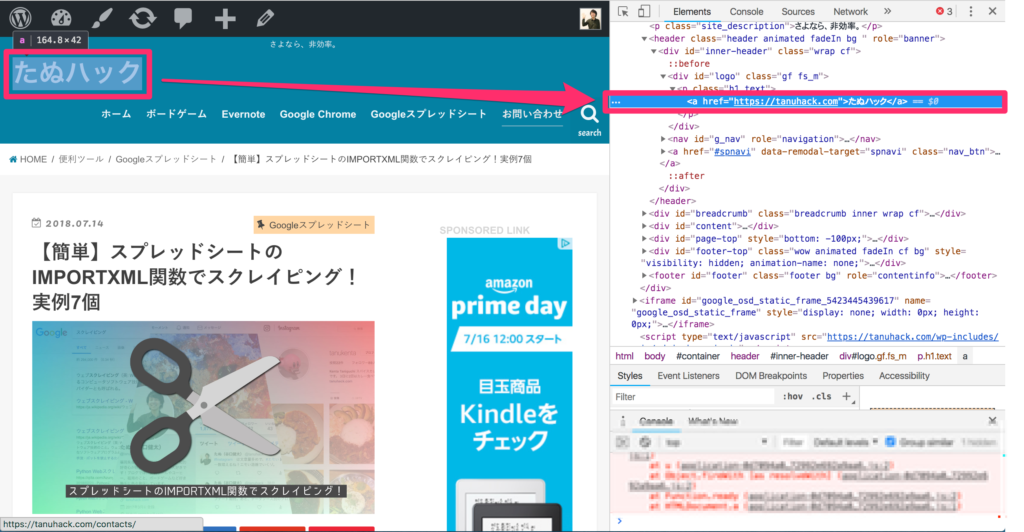
STEP3:[Copy]→[Copy Xpath]を選択
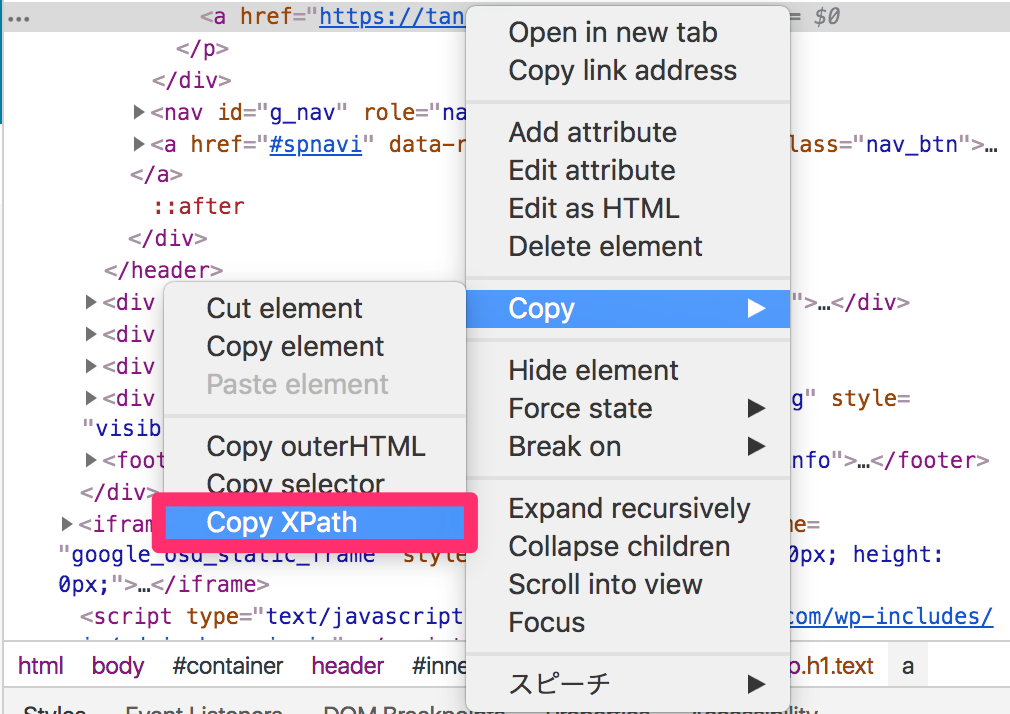
そのまま、[右クリック]→[Copy]→[Copy Xpath]と選択します。
このようなXPathがコピーされていれば成功です!
簡単に説明すると、「HTMLのidがlogoのPタグのAタグの中身を表示します」みたいな感じのことが書いてあります。
ChromeのCopy XPath機能をつかって色んなサイトでスクレイピングしてみましょう!
スクレイピングの実例7個
ここからはIMPORTXML関数を使って、スクレイピングができる汎用性がきっと高いだろうと思われるものを私の独断と偏見で7つ選んでみました。
それぞれ、XPathを記載しているので、コピペでじゃんじゃん使ってください。
- ページのタイトルを取得
- ページのディスクリプションを取得
- ページのキーワードを取得
- Twitterのフォロワー数を取得
- Instagramの情報を取得
- Googleの検索結果を取得
- Googleのサジェストを取得
ページのタイトルを取得

titleタグのコンテンツを取得します。
2018年7月14日現在、ほとんどのサイトがHTML5で作られています。
2000年代初期に作られた化石のようなWebサイト以外は、この記述だけでスクレイピングすることができるはずです。
ページのディスクリプションを取得

サイトの要約文であるmetaタグのディスクリプションを取得します。
ページのキーワードを取得
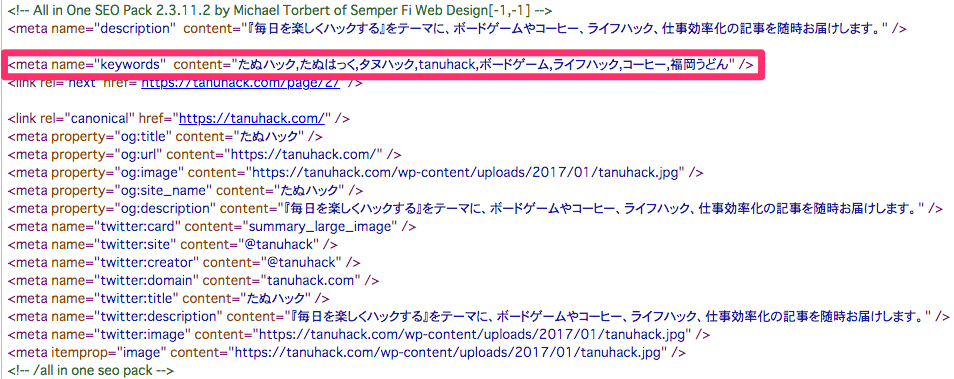
metaタグのキーワードを取得します。
Twitterのフォロワー数を取得
Twitterのフォロワー数もIMPORTXML関数で引っ張ってこれます。
Instagramの情報を取得

フォロワー数やフォロー数、投稿数などを個別に持ってくることが出来ないので、スプレッドシートの関数を使って表示を整えなければいけません。
89 Followers, 71 Following, 22 Posts - See Instagram photos and videos from
Kenta Taniguchi (@tanukenta)
例えば、この情報がC2セル入っているとすれば…

正規表現が使えるREGEXEXTRACT関数で、文字列の中から必要な情報だけ取り出しましょう!
| フォロワー数 | =REGEXEXTRACT(REGEXEXTRACT(C2,"\d+\sFollowers"),"\d*") |
|---|---|
| フォロー数 | =REGEXEXTRACT(REGEXEXTRACT(C2,"\d+\sFollowing"),"\d*") |
| 投稿数 | =REGEXEXTRACT(REGEXEXTRACT(C2,"\d+\sPosts"),"\d*") |
 知らないと損!正規表現を使ってスプレッドシートの文字列を便利に抽出する方法
[aside]補足
知らないと損!正規表現を使ってスプレッドシートの文字列を便利に抽出する方法
[aside]補足
TwitterやInstagramのHTMLのソースを確認すると、JavaScriptでコードが隠されています。
記事数だったり、記事毎のイイネ数やコメント数/内容、投稿時間など引っ張ってくるにはPythonやRubyなどのプログラムでゴリゴリ書かなければいけません(汗)
[/aside]Googleの検索結果を取得
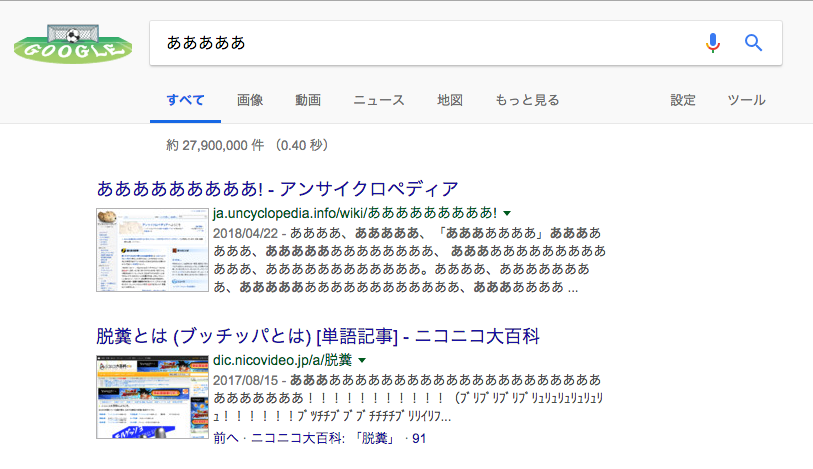
IMPORTXML関数を使えば、なんとGoogleの検索結果も表示することができます。
競合のリサーチや、SEO対策に使えますね!
これとタイトルとディスクリプション、キーワードを組み合わせれば、SEO対策における競合分析のシートをサクッと作ることが出来ます。
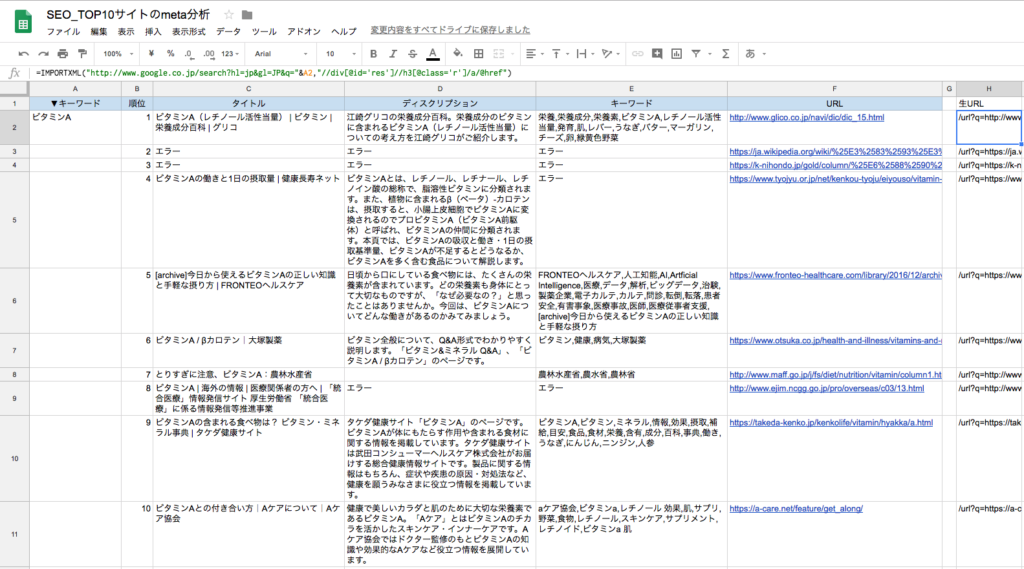
補足になりますが、URLパラメータの部分にnum=30のように追加すれば、そのキーワードにおける1位から30位までのサイトが表示されるようになります。
Googleのサジェストを取得
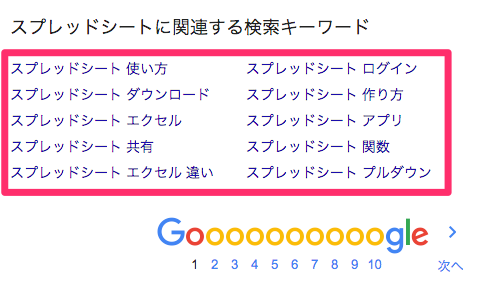
IMPORTXML関数を使えば、検索補完のサジェストも取得することができます。
次に書く記事候補を見つけたいときにおすすめです(^o^)
さいごに
今回は、IMPORTXML関数でスクレイピングする方法を紹介しました。
IMPORTXML関数を使えば、PythonやRubyなどのプログラミングスキルを持たなくても、簡単なスクレイピングなら実行可能です。
スクレイピングを体験して、『機械に仕事をさせてる感覚』を覚えて欲しいなと思います!!
その経験こそが、効率厨にハマる沼でもあるのです。
人間がわざわざ手を下すほどでもない単調な作業は、どんどん機械にやらせよう。
[aside]この記事もオススメですExcelからスプレッドシートに今すぐ乗り換えよう
 スプレッドシートがExcelより優れている5つの理由!今すぐ移行しよう
[/aside]
スプレッドシートがExcelより優れている5つの理由!今すぐ移行しよう
[/aside]
