
こんにちは、データサイエンティストのたぬ(@tanuhack)です!
前処理(=データを分析しやすくするためにデータそのものを整えること)の中でも、今回取り上げている『抽出』という作業は、無駄な処理を減らしたり、扱うデータの量を小さくしたりすることが出来るので、何が何でも外せません。
そこで今回は、Rでお馴染みのアヤメの統計データを元に、なるべく具体例を取り込みながらデータを抽出する方法を3つ紹介します。
import pandas as pd
import seaborn as sns # ==> pip install seaborn
## アヤメの統計データをPandasのDataFrameで格納する
# sepal_length:がく片の長さ(4.3~7.9)
# sepal_width :がく片の幅(2.0~4.4)
# petal_length:花びらの長さ(1.3~6.9)
# petal_width :花びらの幅(0.1~2.5)
# species :アヤメの種類(setosa, versicolor, virginica)
iris = sns.load_dataset('iris') 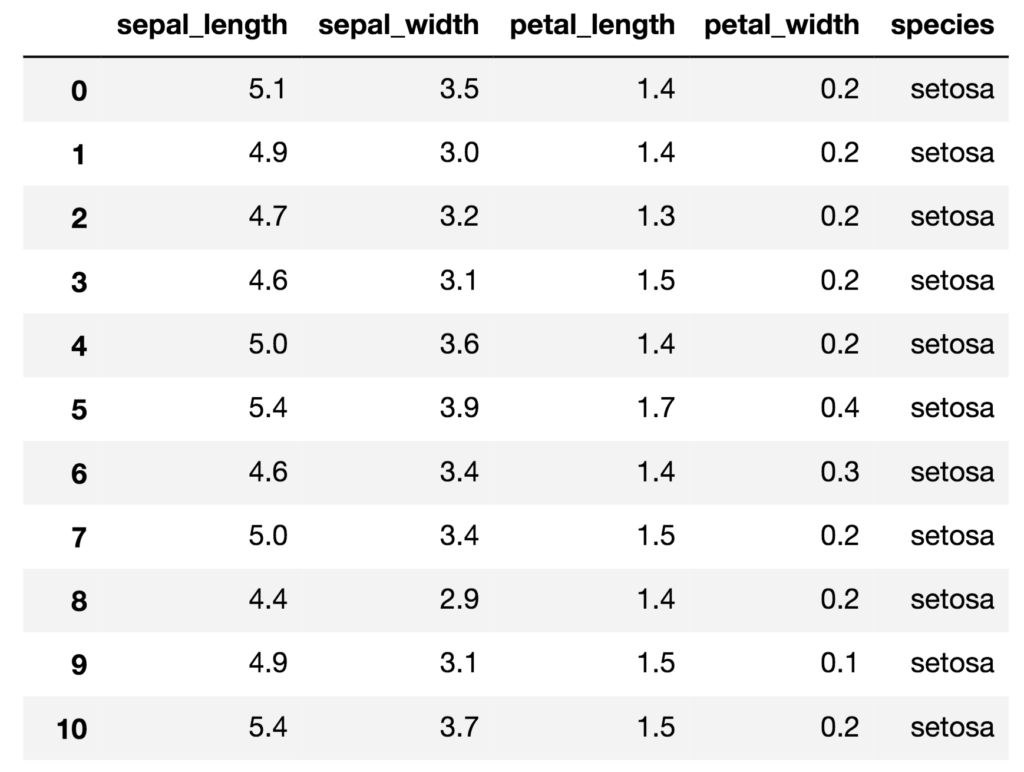
目次

データサイエンティスト / ブロガー
たぬ
tanu
福岡在住のデータサイエンティスト。Pythonでルーチンワークを瞬殺する仕組みを作ることやデータを視覚化することが得意です。
データ列指定による抽出
列を抽出する方法はいくつかありますが、今回はコードを書いた後の可読性を踏まえた上でオススメなものを紹介します。
列名を直接指定する
例として、sepal_lengthとsepal_widthの列だけを抽出するものとします。
# 方法1:列名を直接指定する
# カンマで複数列選択も可
iris[['sepal_length','sepal_width']]
# 方法2:loc関数の2次元配列の2次元目に抽出したい列名を指定することで、列を抽出することも出来る
# 1次元目の:は、全てを選択するという意味の値
iris.loc[:, ['sepal_length','sepal_width']]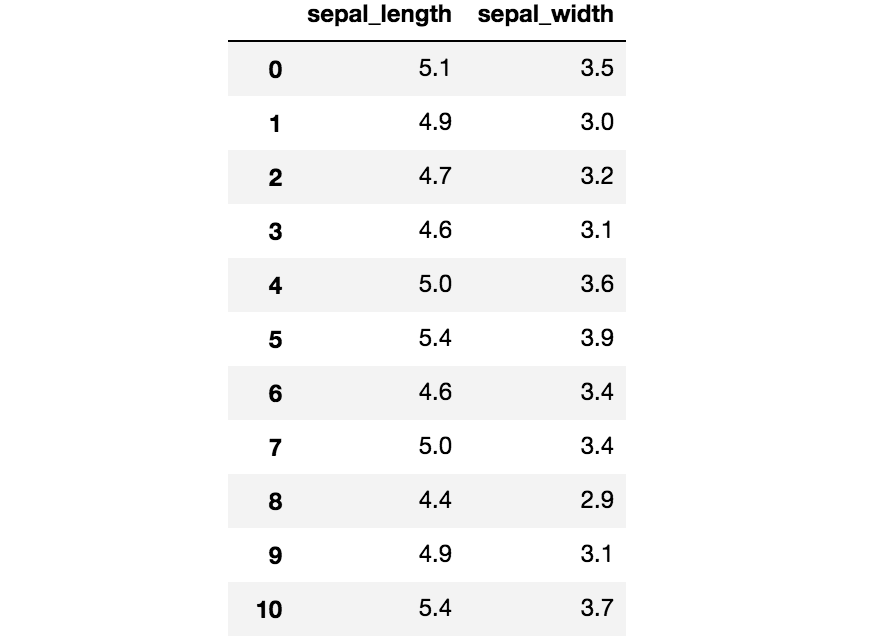
drop関数で不要な列を削除する
先程のものとは少し違い、不要な列名を全部削除した結果、残ったものが本来抽出したかったものになります。
可読性は少し下がりますが、処理が軽くなるので、膨大な量のテーブルを操作している場合は、一考の余地ありです。
# 第一引数:不要な列をlistで設置
# 第二引数:axis=1で列を削除する(行を削除したい場合は、axis=1)
# 第三引数:inplace=TrueでもともとのDataFrameを上書きする
iris.drop(['petal_length','petal_width','species'],axis=1, inplace=True)
条件指定による抽出
query関数
イコールや大小比較、AND条件、OR条件、NOT条件などはpd.DataFrame.query('条件指定')で、簡単に条件指定してデータを抽出することが出来ます。
正規表現や部分一致で条件指定を行いたい場合は、query()では出来ないので、注意が必要です。(※後述)
CASE1:単一条件でセグメントしたい
# petal_lengthが3より大きいものだけ抽出
iris.query('petal_length > 3')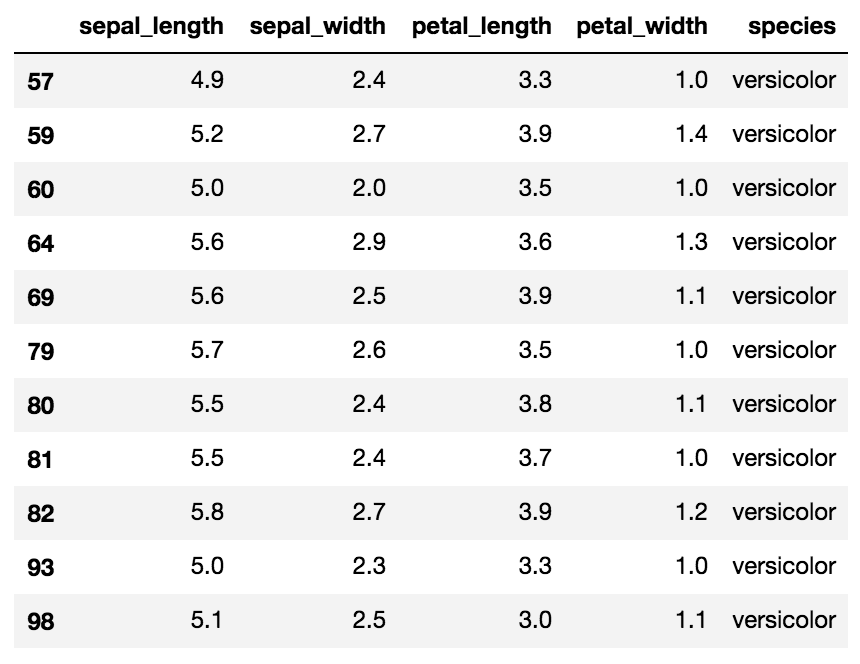
CASE2:複数条件でセグメントしたい
| AND条件 | & |
|---|---|
| OR条件 | | |
# speciesがversicolorかつ、petal_lengthが3.0以上〜4.0未満のものだけ抽出
# 文字列はダブルクォーテーションで
iris.query('3 <= petal_length < 4 & species=="versicolor"')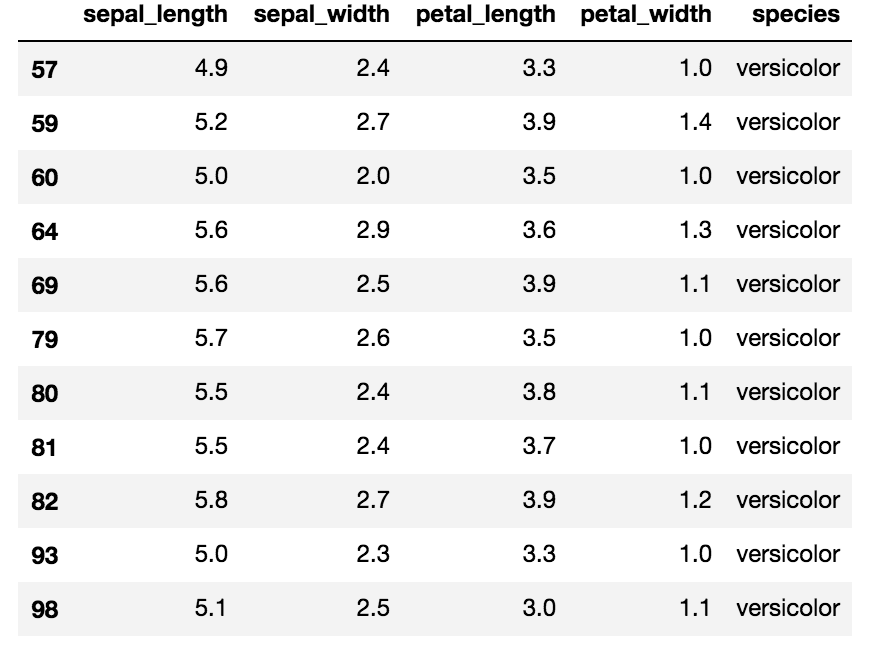
CASE3:not条件でセグメントしたい
| not条件 | not |
|---|
# speciesがversicolorかつsetosaでないものだけを抽出
iris.query('not species=="versicolor" & not species=="setosa"')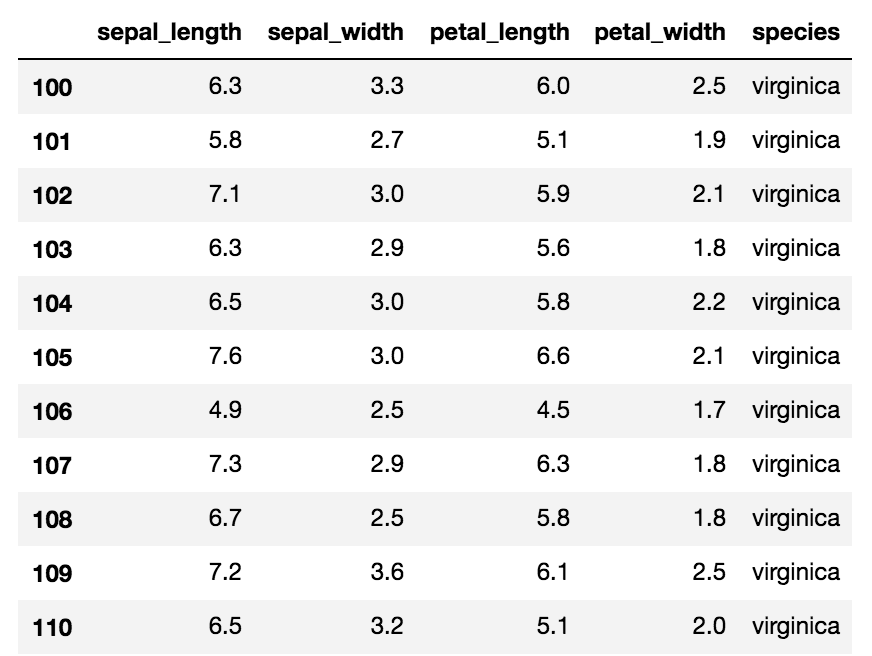
部分一致や正規表現で条件指定する
完全にテーブルの値の名前を覚えていないときって結構あると思うんですよね。
そんなとき、部分一致や正規表現が使えたら便利だと思いませんか?
| 部分一致 | pd.Series.str.contains('文字列') |
|---|---|
| 正規表現 | pd.Series.str.match('正規表現') |
気を付けるポイントは、DataFrame→Series→DataFrameに変換しなければいけないことです。(※データフレームの状態で直接、部分一致や正規表現を使えないため)
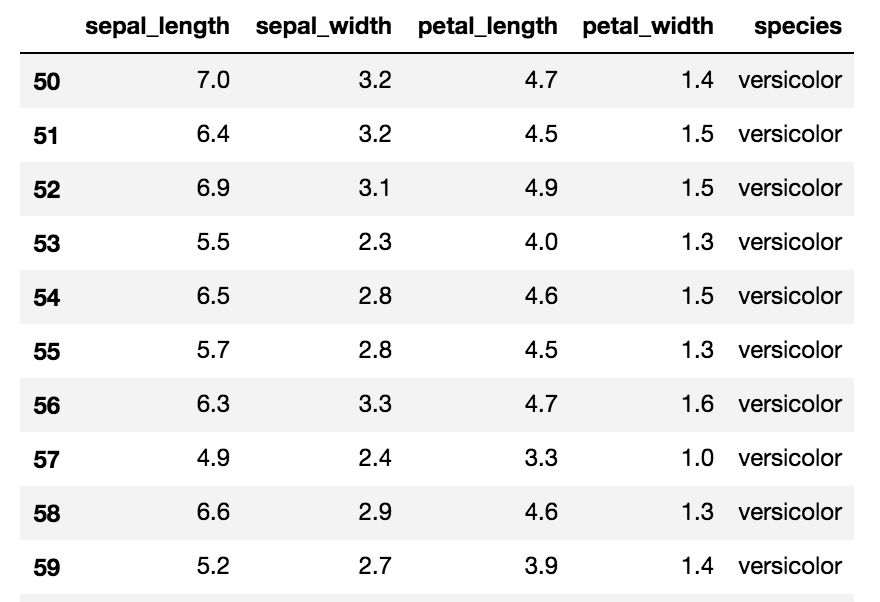
## species列で『ver』が含まれる種類のものだけを表示させる
# 部分一致
iris[iris['species'].str.contains('ver', na=False)]
# 正規表現
iris[iris['species'].str.match('ver.*', na=False)]
ランダムサンプリングによる抽出
最後はランダムサンプリング(完全無作為抽出)によるデータの抽出です。
Pythonでは、pd.DataFrame.sample()で簡単にランダムサンプリングを行うことが出来ます。
| 50%サンプリング | sample(frac=0.5) |
|---|---|
| 50件抽出 | sample(50) |
データ値に基づかないサンプリング
元データから単純にサンプリングする場合は以下のように設定します。
# 50件だけをランダム抽出
iris.sample(50)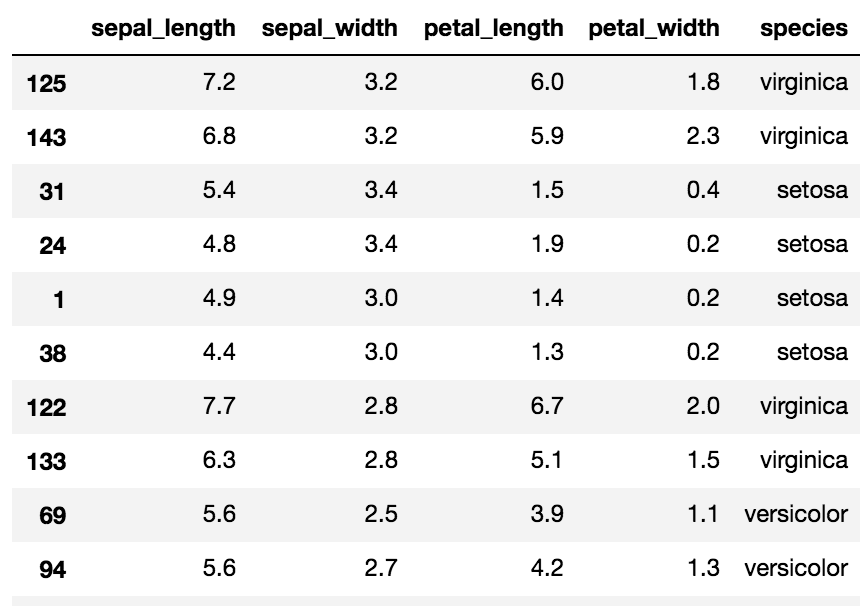
さいごに
今回は、前処理の基本中の基本である『抽出』作業について紹介しました。
繰り返しになりますが、抽出は無駄な処理を減らしたり、扱うデータの量を小さくしたりすることが出来るので、効率よく分析するためには欠かせないスキルです。
しっかり習得して、スーパーなデータサイエンティストを目指しましょう!
それでは



